Interactive code examples for fun and profit
I believe that most of technical writing — from product documentation to online courses to blog posts — benefits from code examples. Especially when those examples are interactive, meaning the reader can run/modify them without leaving the docs or installing anything.
Let me prove my point by showing you some scenarios involving interactive code snippets. I'll also show how to implement such scenarios using an open source tool I've developed for this very purpose.
Tutorials • Release notes • Reference documentation • Blogging • Education • Implementation
Tutorials and how-to guides
📝 Use case: You are the developer of the Gists service, which provides a hassle-free storage for code snippets (called "gists"). You'd like to teach developers how to use your API.
Let's take a look at the public gists of the certain user (rednafi). The response can be quite chatty, so we'll only select the most recent (per_page = 1):
GET https://api.github.com/users/rednafi/gists?per_page=1
accept: application/json
HTTP/1.1 200
cache-control: public, max-age=60, s-maxage=60
content-length: 770
content-type: application/json; charset=utf-8
etag: W/"980aca0dc5f96f11f648def49792bcf14dd0c9e464d9dfee13de30fb3be86055"
link: <https://api.github.com/user/30027932/gists?per_page=1&page=2>; rel="next", <https://api.github.com/user/30027932/gists?per_page=1&page=41>; rel="last"
x-github-media-type: github.v3
x-github-request-id: CAFF:7A048:3CE23E:453A6C:6730EBB7
x-ratelimit-limit: 60
x-ratelimit-remaining: 58
x-ratelimit-reset: 1731262890
x-ratelimit-resource: core
x-ratelimit-used: 2
[
{
"url": "https://api.github.com/gists/61b0e6a685ffd9cd09bf978565e7f7f7",
"forks_url": "https://api.github.com/gists/61b0e6a685ffd9cd09bf978565e7f7f7/forks",
"commits_url": "https://api.github.com/gists/61b0e6a685ffd9cd09bf978565e7f7f7/commits",
"id": "61b0e6a685ffd9cd09bf978565e7f7f7",
"node_id": "G_kwDOAcownNoAIDYxYjBlNmE2ODVmZmQ5Y2QwOWJmOTc4NTY1ZTdmN2Y3",
"git_pull_url": "https://gist.github.com/61b0e6a685ffd9cd09bf978565e7f7f7.git",
"git_push_url": "https://gist.github.com/61b0e6a685ffd9cd09bf978565e7f7f7.git",
"html_url": "https://gist.github.com/rednafi/61b0e6a685ffd9cd09bf978565e7f7f7",
"files": {
"worklog.md": {
"filename": "worklog.md",
"type": "text/markdown",
"language": "Markdown",
"raw_url": "https://gist.githubusercontent.com/rednafi/61b0e6a685ffd9cd09bf978565e7f7f7/raw/7e3458768a950ba01bb1d0686f41a06060f10c9e/worklog.md",
"size": 6997
}
},
"public": true,
"created_at": "2024-08-19T17:10:50Z",
"updated_at": "2024-08-20T07:14:13Z",
"description": "Generate a simple worklog. ",
"comments": 0,
"user": null,
"comments_url": "https://api.github.com/gists/61b0e6a685ffd9cd09bf978565e7f7f7/comments",
"owner": {
"login": "rednafi",
"id": 30027932,
"node_id": "MDQ6VXNlcjMwMDI3OTMy",
"avatar_url": "https://avatars.githubusercontent.com/u/30027932?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rednafi",
"html_url": "https://github.com/rednafi",
"followers_url": "https://api.github.com/users/rednafi/followers",
"following_url": "https://api.github.com/users/rednafi/following{/other_user}",
"gists_url": "https://api.github.com/users/rednafi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rednafi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rednafi/subscriptions",
"organizations_url": "https://api.github.com/users/rednafi/orgs",
"repos_url": "https://api.github.com/users/rednafi/repos",
"events_url": "https://api.github.com/users/rednafi/events{/privacy}",
"received_events_url": "https://api.github.com/users/rednafi/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"truncated": false
}
]
We can see that the gist is identified by an id or an url, and that it has created_at and updated_at timestamps, as well as lots of other metadata. However, the actual gist content is not returned (which seems logical, since this is a "list all" method).
To see the file contents, let's take a look at the specific gist with id aee0d31ae5a1053c5297de0430fa87c7:
GET https://api.github.com/gists/aee0d31ae5a1053c5297de0430fa87c7
accept: application/json
HTTP/1.1 200
cache-control: public, max-age=60, s-maxage=60
content-length: 1088
content-type: application/json; charset=utf-8
etag: W/"ba169776822bc2e63d553b340f88220d9324db4d482353bf33762eccb8de8849"
last-modified: Sun, 10 Nov 2024 17:28:35 GMT
x-github-media-type: github.v3
x-github-request-id: CC36:E577A:1006A6:12ACA8:6730ED53
x-ratelimit-limit: 60
x-ratelimit-remaining: 54
x-ratelimit-reset: 1731262890
x-ratelimit-resource: core
x-ratelimit-used: 6
{
"url": "https://api.github.com/gists/aee0d31ae5a1053c5297de0430fa87c7",
"forks_url": "https://api.github.com/gists/aee0d31ae5a1053c5297de0430fa87c7/forks",
"commits_url": "https://api.github.com/gists/aee0d31ae5a1053c5297de0430fa87c7/commits",
"id": "aee0d31ae5a1053c5297de0430fa87c7",
"node_id": "G_kwDOACz0htoAIGFlZTBkMzFhZTVhMTA1M2M1Mjk3ZGUwNDMwZmE4N2M3",
"git_pull_url": "https://gist.github.com/aee0d31ae5a1053c5297de0430fa87c7.git",
"git_push_url": "https://gist.github.com/aee0d31ae5a1053c5297de0430fa87c7.git",
"html_url": "https://gist.github.com/nalgeon/aee0d31ae5a1053c5297de0430fa87c7",
"files": {
"greet.py": {
"filename": "greet.py",
"type": "application/x-python",
"language": "Python",
"raw_url": "https://gist.githubusercontent.com/nalgeon/aee0d31ae5a1053c5297de0430fa87c7/raw/34867bd4013c17db4847fb67ad713b9592dd27d7/greet.py",
"size": 192,
"truncated": false,
"content": "class Greeter:\n def __init__(self, greeting):\n self.greeting = greeting\n\n def greet(self, who):\n print(f\"{self.greeting}, {who}!\")\n\ngr = Greeter(\"Hello\")\ngr.greet(\"world\")\n"
}
},
"public": false,
"created_at": "2024-11-10T17:28:35Z",
"updated_at": "2024-11-10T17:28:35Z",
"description": "",
"comments": 0,
"user": null,
"comments_url": "https://api.github.com/gists/aee0d31ae5a1053c5297de0430fa87c7/comments",
"owner": {
"login": "nalgeon",
"id": 2946182,
"node_id": "MDQ6VXNlcjI5NDYxODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2946182?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nalgeon",
"html_url": "https://github.com/nalgeon",
"followers_url": "https://api.github.com/users/nalgeon/followers",
"following_url": "https://api.github.com/users/nalgeon/following{/other_user}",
"gists_url": "https://api.github.com/users/nalgeon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nalgeon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nalgeon/subscriptions",
"organizations_url": "https://api.github.com/users/nalgeon/orgs",
"repos_url": "https://api.github.com/users/nalgeon/repos",
"events_url": "https://api.github.com/users/nalgeon/events{/privacy}",
"received_events_url": "https://api.github.com/users/nalgeon/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"forks": [
],
"history": [
{
"user": {
"login": "nalgeon",
"id": 2946182,
"node_id": "MDQ6VXNlcjI5NDYxODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2946182?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nalgeon",
"html_url": "https://github.com/nalgeon",
"followers_url": "https://api.github.com/users/nalgeon/followers",
"following_url": "https://api.github.com/users/nalgeon/following{/other_user}",
"gists_url": "https://api.github.com/users/nalgeon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nalgeon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nalgeon/subscriptions",
"organizations_url": "https://api.github.com/users/nalgeon/orgs",
"repos_url": "https://api.github.com/users/nalgeon/repos",
"events_url": "https://api.github.com/users/nalgeon/events{/privacy}",
"received_events_url": "https://api.github.com/users/nalgeon/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"version": "308812811edea891e57e9dad85b57f758f581fd1",
"committed_at": "2024-11-10T17:28:34Z",
"change_status": {
"total": 9,
"additions": 9,
"deletions": 0
},
"url": "https://api.github.com/gists/aee0d31ae5a1053c5297de0430fa87c7/308812811edea891e57e9dad85b57f758f581fd1"
}
],
"truncated": false
}
Again, the response is quite chatty, but we can see that there is a greet.py file written in the Python language with some content. Let's try running it:
class Greeter:
def __init__(self, greeting):
self.greeting = greeting
def greet(self, who):
print(f"{self.greeting}, {who}!")
gr = Greeter("Hello")
gr.greet("world")
...
Works like a charm!
The tutorial could go on, but I think you get the idea (if you'd like a more complete example, see the API tutorials beyond OpenAPI post). Let's move on to the next use case.
Release notes
📝 Use case: You are the developer of the SQLite database engine. You'd like to show some nice features and improvements you've added in the new 3.44 release.
One of the major 3.44 changes is that aggregate functions now accept an optional order by after the last parameter. It defines an order in which the function processes its arguments.
order by in aggregates is probably not very useful in avg, count and other functions whose result does not depend on the order of the arguments. However, it can be quite handy for functions like group_concat and json_group_array.
Let's say we have an employees table:
select * from employees;
┌────┬───────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼───────┼────────┼────────────┼────────┤
│ 11 │ Diane │ London │ hr │ 70 │
│ 12 │ Bob │ London │ hr │ 78 │
│ 21 │ Emma │ London │ it │ 84 │
│ 22 │ Grace │ Berlin │ it │ 90 │
│ 23 │ Henry │ London │ it │ 104 │
│ 24 │ Irene │ Berlin │ it │ 104 │
│ 31 │ Cindy │ Berlin │ sales │ 96 │
│ 32 │ Dave │ London │ sales │ 96 │
└────┴───────┴────────┴────────────┴────────┘
Suppose we want to show employees who work in each of the departments, so we group by department and use group_concat on the name. Previously, we had to rely on the default record order. But now we can concatenate the employees in straight or reverse alphabetical order (or any other order — try changing the order by clause below):
select
department,
group_concat(name order by name desc) as names
from employees
group by department;
┌────────────┬────────────────────────┐
│ department │ names │
├────────────┼────────────────────────┤
│ hr │ Diane,Bob │
│ it │ Irene,Henry,Grace,Emma │
│ sales │ Dave,Cindy │
└────────────┴────────────────────────┘
Now let's group employees by city using json_group_array:
select
value ->> 'city' as city,
json_group_array(
value -> 'name' order by value ->> 'id'
) as json_names
from
json_each(readfile('src/employees.json'))
group by
value ->> 'city'
┌────────┬───────────────────────────────────────────────────────────────┐
│ city │ json_names │
├────────┼───────────────────────────────────────────────────────────────┤
│ Berlin │ ["\"Grace\"","\"Irene\"","\"Frank\"","\"Cindy\"","\"Alice\""] │
│ London │ ["\"Diane\"","\"Bob\"","\"Emma\"","\"Henry\"","\"Dave\""] │
└────────┴───────────────────────────────────────────────────────────────┘
Nice!
SQLite 3.44 brought more features, but again, I think you get the idea. Let's move on to the next use case.
Reference documentation
📝 Use case: You are the author of the curl tool. You decide to include playgrounds in the product man page so that people do not have to go back to their terminals to try different command line options.
--json <data>
Sends the specified JSON data in a POST request to the HTTP server. --json works as a shortcut for passing on these three options:
--data [arg]
--header "Content-Type: application/json"
--header "Accept: application/json"
If this option is used more than once on the same command line, the additional data pieces are concatenated to the previous before sending.
If you start the data with the letter @, the rest should be a file name to read the data from, or a single dash (-) if you want curl to read the data from stdin. Posting data from a file named 'foobar' would thus be done with --json @foobar and to instead read the data from stdin, use --json @-.
The headers this option sets can be overridden with -H, --header as usual.
Examples:
curl --json '{ "drink": "coffee" }' http://httpbingo.org/anything
{
"args": {},
"headers": {},
"method": "POST",
"origin": "172.19.0.9:39794",
"url": "http://httpbingo.org/anything",
"data": "{ \"drink\": \"coffee\" }",
"files": {},
"form": {},
"json": {
"drink": "coffee"
}
}
curl --json '[' --json '1,2,3' --json ']' http://httpbingo.org/anything
{
"args": {},
"headers": {},
"method": "POST",
"origin": "172.19.0.9:34086",
"url": "http://httpbingo.org/anything",
"data": "[1,2,3]",
"files": {},
"form": {},
"json": [
1,
2,
3
]
}
curl --json @coffee.json http://httpbingo.org/anything
{
"args": {},
"headers": {},
"method": "POST",
"origin": "172.19.0.9:35124",
"url": "http://httpbingo.org/anything",
"data": "{ \"drink\": \"coffee\" }\n",
"files": {},
"form": {},
"json": {
"drink": "coffee"
}
}
If you want to try more curl examples, see the Curl by example interactive guide. Now let's move on to the next use case.
Blogging
📝 Use case: you are sharing your experience of comparing different object implementations in Python to make them use as little memory as possible.
Imagine you have a simple Pet object with the name (string) and price (integer) attributes. Intuitively, it seems that the most compact representation is a tuple:
("Frank the Pigeon", 50000)
Let's measure how much memory this beauty eats:
import random
import string
from pympler.asizeof import asizeof
def fields():
name_gen = (random.choice(string.ascii_uppercase) for _ in range(10))
name = "".join(name_gen)
price = random.randint(10000, 99999)
return (name, price)
def measure(name, fn, n=10_000):
pets = [fn() for _ in range(n)]
size = round(asizeof(pets) / n)
print(f"Pet size ({name}) = {size} bytes")
return size
baseline = measure("tuple", fields)
Pet size (tuple) = 161 bytes
161 bytes. Let's use that as a baseline for further comparison.
Since nobody works with tuples these days, you would probably choose a dataclass:
from dataclasses import dataclass
@dataclass
class PetData:
name: str
price: int
fn = lambda: PetData(*fields())
base = measure("baseline", fields)
measure("dataclass", fn, baseline=base)
Pet size (baseline) = 161 bytes
Pet size (dataclass) = 233 bytes
x1.45 to baseline
Thing is, it's 1.5 times larger than a tuple.
Let's try a named tuple then:
from typing import NamedTuple
class PetTuple(NamedTuple):
name: str
price: int
fn = lambda: PetTuple(*fields())
base = measure("baseline", fields)
measure("named tuple", fn, baseline=base)
Pet size (baseline) = 161 bytes
Pet size (named tuple) = 161 bytes
x1.00 to baseline
Looks like a dataclass, works like a tuple. Perfect. Or not?
If you are into Python, see further comparison in the Compact objects in Python post. Better yet, save that for later and let's move on to the next use case.
Education
📝 Use case: You are teaching a "Modern SQL" course. In one of the lessons, you explain the standard way of limiting the result rows of a SELECT query.
You are probably familiar with the limit clause, which returns the first N rows according to the order by:
select * from employees
order by salary desc
limit 5;
┌────┬───────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼───────┼────────┼────────────┼────────┤
│ 23 │ Henry │ London │ it │ 104 │
│ 24 │ Irene │ Berlin │ it │ 104 │
│ 32 │ Dave │ London │ sales │ 96 │
│ 31 │ Cindy │ Berlin │ sales │ 96 │
│ 22 │ Grace │ Berlin │ it │ 90 │
└────┴───────┴────────┴────────────┴────────┘
But although limit is widely supported, it's not part of the SQL standard. The standard (as of SQL:2008) dictates that we use fetch:
select * from employees
order by salary desc
fetch first 5 rows only;
┌────┬───────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼───────┼────────┼────────────┼────────┤
│ 23 │ Henry │ London │ it │ 104 │
│ 24 │ Irene │ Berlin │ it │ 104 │
│ 32 │ Dave │ London │ sales │ 96 │
│ 31 │ Cindy │ Berlin │ sales │ 96 │
│ 22 │ Grace │ Berlin │ it │ 90 │
└────┴───────┴────────┴────────────┴────────┘
fetch first N rows only does exactly what limit N does (but it can do more).
fetch plays well with offset, as does limit. Try writing a query that fetches the next 2 records after skipping the first 5:
select id from employees
order by city, id
offset 5 fetch ...;
If you want to learn more about FETCH, see the LIMIT vs. FETCH in SQL post. In the meantime, let's move on to the implementation.
Implementation
As I mentioned earlier, I believe that most of technical writing benefits from interactive examples. So I've built and open-sourced Codapi — a platform for embedding interactive code snippets virtually anywhere.
Codapi manages sandboxes (isolated execution environments) and provides an API to execute code in these sandboxes. It also provides a JavaScript widget for easier integration.
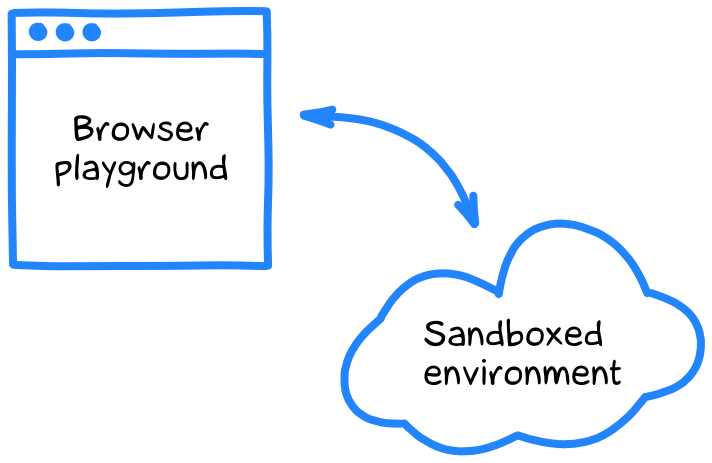
Interactive code snippets
On the frontend, Codapi is very non-invasive. Given you already have static code examples in your docs, all you need to do is to add a codapi-snippet for each code sample like this:
<!-- existing code snippet -->
<pre>
def greet(name):
print(f"Hello, {name}!")
greet("World")
</pre>
<!-- codapi widget -->
<codapi-snippet sandbox="python" editor="basic"> </codapi-snippet>
The widget attaches itself to the preceding code block, allowing the reader to run and edit the code like this:
def greet(name):
print(f"Hello, {name}!")
greet("World")
The widget offers a range of customization options and advanced features such as templates and multi-file playgrounds. There are also integration guides for popular platforms such as WordPress, Notion or Docusaurus.
Sandboxed environments
Some playgrounds (namely JavaScript, Python, PHP, Ruby, Lua, SQLite and PostgreSQL) work entirely in the browser using WebAssembly. Others require a sandbox server.
On the backend, a Codapi sandbox is a thin layer over one or more Docker containers, accompanied by a config file that describes which commands to run in those containers.
┌──────────────────────────┐ ┌────────┐
│ execution + API │ → │ config │
└──────────────────────────┘ └────────┘
┌────────┐ ┌──────┐ ┌───────┐ ┌──────┐
│ python │ │ rust │ │ mysql │ │ curl │ ...
└────────┘ └──────┘ └───────┘ └──────┘
╰ containers
For example, here is a config for the run command in the python sandbox:
{
"engine": "docker",
"entry": "main.py",
"steps": [
{
"box": "python",
"command": ["python", "main.py"]
}
]
}
This is essentially what it says:
When the client executes the
runcommand in thepythonsandbox, save their code to themain.pyfile, then run it in thepythonbox (Docker container) using thepython main.pyshell command.
And here is a (slightly more complicated) config for the mysql sandbox:
{
"engine": "docker",
"before": {
"box": "mysql",
"user": "root",
"action": "exec",
"command": ["sh", "/etc/mysql/database-create.sh", ":name"]
},
"steps": [
{
"box": "mysql-client",
"stdin": true,
"command": [
"mysql",
"--host",
"mysql",
"--user",
":name",
"--database",
":name",
"--table"
]
}
],
"after": {
"box": "mysql",
"user": "root",
"action": "exec",
"command": ["sh", "/etc/mysql/database-drop.sh", ":name"]
}
}
As you can see, it involves two containers (MySQL server and client) and additional setup/teardown steps to create and destroy the database.
Thanks to Dockerfiles and declarative sandbox configs, Codapi is not limited to a fixed set of programming languages, databases and tools. You can build your own sandboxes with custom packages and software, and use them for fun and profit.
Using Codapi
Codapi is available as a cloud service and as a self-hosted version. It is licensed under the permissive Apache-2.0 license and is committed to remaining open source forever.
Here is how to get started with the self-hosted version:
If you prefer the cloud version, just start using the widget, no signup required.
In any case, I encourage you to give Codapi a try. Let's make the world of technical documentation a little better!
★ Subscribe to keep up with new posts.