SQL Cheat Sheet
This is a short cheat sheet for those who were once familiar with SQL selects, but haven't given it much practice since. The examples are interactive, so you can both read and practice.
We will use the toy employees table:
┌────┬───────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼───────┼────────┼────────────┼────────┤
│ 11 │ Diane │ London │ hr │ 70 │
│ 12 │ Bob │ London │ hr │ 78 │
│ 21 │ Emma │ London │ it │ 84 │
│ 22 │ Grace │ Berlin │ it │ 90 │
│ 23 │ Henry │ London │ it │ 104 │
│ 24 │ Irene │ Berlin │ it │ 104 │
│ 25 │ Frank │ Berlin │ it │ 120 │
│ 31 │ Cindy │ Berlin │ sales │ 96 │
│ 32 │ Dave │ London │ sales │ 96 │
│ 33 │ Alice │ Berlin │ sales │ 100 │
└────┴───────┴────────┴────────────┴────────┘
Basics
The basic building blocks of an SQL query.
select ... from ...
Selects rows from the specified table, keeping only the listed columns in each row.
select id, name, salary
from employees;
where
Select only rows that meet the conditions.
select id, name, salary
from employees
where city = 'Berlin';
There are different types of conditions:
- strict equality:
city = 'Berling' - inequality:
salary > 100 - range inclusion:
id between 20 and 29 - set inclusion:
department in ('hr', 'it') - pattern matching:
name like 'A%' - null value checking:
city is null
Conditions can be combined with or (to select rows that match any of the conditions):
select id, name, salary
from employees
where department = 'hr' or department = 'it';
Or with and (to select rows that match all of the conditions):
select id, name, salary
from employees
where city = 'London' and department = 'it';
distinct
Selects only unique values (i.e., no repetitions) listed in the select columns.
select distinct department
from employees;
order by
Sorts the results according to the specified columns.
select id, name, salary
from employees
order by salary, id;
Sorts from smallest to largest by default, but does the opposite if you add desc.
select id, name, salary
from employees
order by salary desc, id;
limit
Returns only the first N rows of the result set. Typically used with order by.
select id, name, salary
from employees
order by salary
limit 5;
Grouping
Grouping data and calculating aggregates.
group by
Combines rows with the same value in specified columns. It is used in conjunction with one of several aggregate functions:
count(*) counts the number of rows with the same group by column value.
-- number of employees in each city
select city, count(*)
from employees
group by city;
sum(column) calculates the sum of the column values among the rows with the same group by column value.
-- total salary fund in each city
select city, sum(salary)
from employees
group by city;
avg(column) calculates the average of the column values among the rows with the same group by column value.
-- average salary in each city
select city, avg(salary)
from employees
group by city;
max(column) calculates the maximum of the column values among the rows with the same group by column value.
-- maximum salary in each city
select city, max(salary)
from employees
group by city;
min(column) calculates the minimum of the column values among the rows with the same group by column value.
-- minimum salary in each city
select city, min(salary)
from employees
group by city;
We can group by multiple columns:
-- average salary in each department for each city
select
city, department,
round(avg(salary)) as avg_salary
from employees
group by city, department;
having
Filters rows from the result after the group by is executed — unlike where, which filters out rows before the group by is executed.
-- departments with more than 3 employees
select department, count(*)
from employees
group by department
having count(*) > 3;
Table join
Merging multiple tables in the query result.
Suppose there are two tables — jobs and companies.
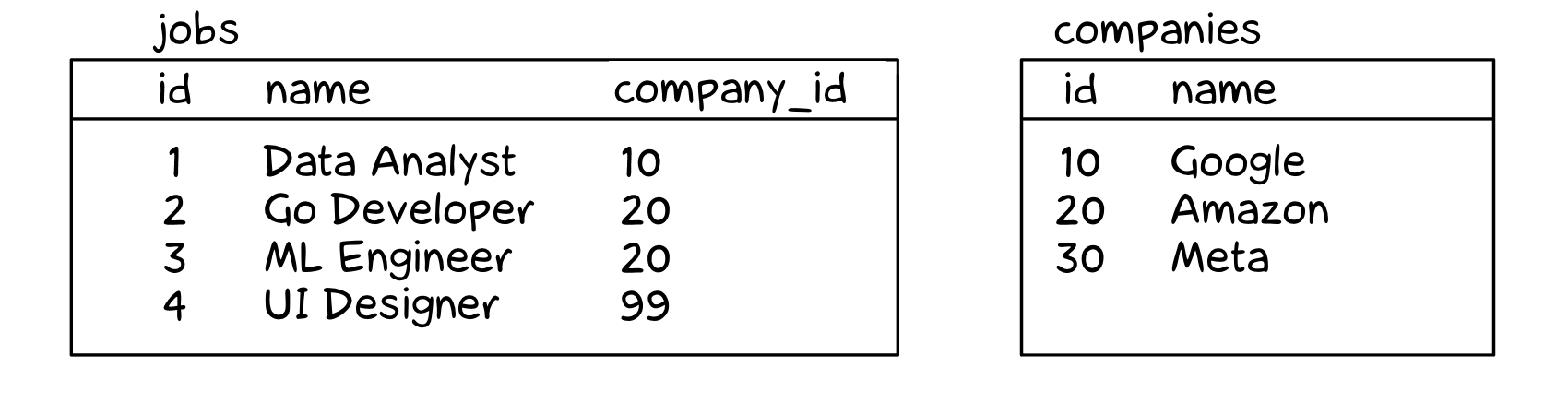
In the jobs table there is a company identifier called company_id. However, the name of the company is in the other table — companies.
Inner JOIN
We want to select records from the jobs table, but we also want to add the company name to them. We can do this by using a table join operation:

select
jobs.id,
jobs.name,
jobs.company_id,
companies.name as company_name
from jobs
join companies on jobs.company_id = companies.id;
For each row in the jobs table, the database engine looks in the companies table, finds the value where id = jobs.company_id, extracts the name, and adds it to the result. If no matching value is found (as in the case of "UI Designer" with a company ID of 99), the row is not included in the result.
Left outer JOIN
A left outer join is very similar to an inner join.

select
jobs.id,
jobs.name,
jobs.company_id,
companies.name as company_name
from jobs
left join companies on jobs.company_id = companies.id;
The difference is that even if the row with id = jobs.company_id ("UI Designer" in our example) is not found in the companies table, the row from jobs will still appear in the result. The company name will be null in this case.
An inner JOIN can be thought of as saying:
Given these two tables, I want to see records that match based on the specified criteria.
A left outer JOIN, on the other hand, says:
Given these two tables, I want to see records that match based on the specified criteria. I also want to see all records from the left table that do not match the right table.
Besides left outer joins, there are also right outer and full outer joins. See SQL join flavors for details.
Summary
We covered the basics of SQL for selecting data:
- Query parts: columns, tables, filtering, sorting.
- Data grouping and aggregation functions.
- Table joins.
Of course, SQL has many more capabilities, but that's another story.
P.S. Interested in mastering advanced SQL? Check out my book — SQL Window Functions Explained
★ Subscribe to keep up with new posts.