SQL window functions: Aggregation
This is a chapter from my book SQL Window Functions Explained. The book is a clear and visual introduction to the topic with lots of practical exercises.
Previously we've covered ranking and offset window functions.
Aggregation means counting totals or averages (or other aggregates). For example, the average salary per city. Or the total number of gold medals for each country in the Olympic Games standings.
We will aggregate records from the employees table:
┌────┬───────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼───────┼────────┼────────────┼────────┤
│ 11 │ Diane │ London │ hr │ 70 │
│ 12 │ Bob │ London │ hr │ 78 │
│ 21 │ Emma │ London │ it │ 84 │
│ 22 │ Grace │ Berlin │ it │ 90 │
│ 23 │ Henry │ London │ it │ 104 │
│ 24 │ Irene │ Berlin │ it │ 104 │
│ 25 │ Frank │ Berlin │ it │ 120 │
│ 31 │ Cindy │ Berlin │ sales │ 96 │
│ 32 │ Dave │ London │ sales │ 96 │
│ 33 │ Alice │ Berlin │ sales │ 100 │
└────┴───────┴────────┴────────────┴────────┘
Table of contents:
Partitioned aggregates
Each department has a salary fund — money spent monthly on paying employees' salaries. Let's see what percentage of this fund represents each employee's salary:
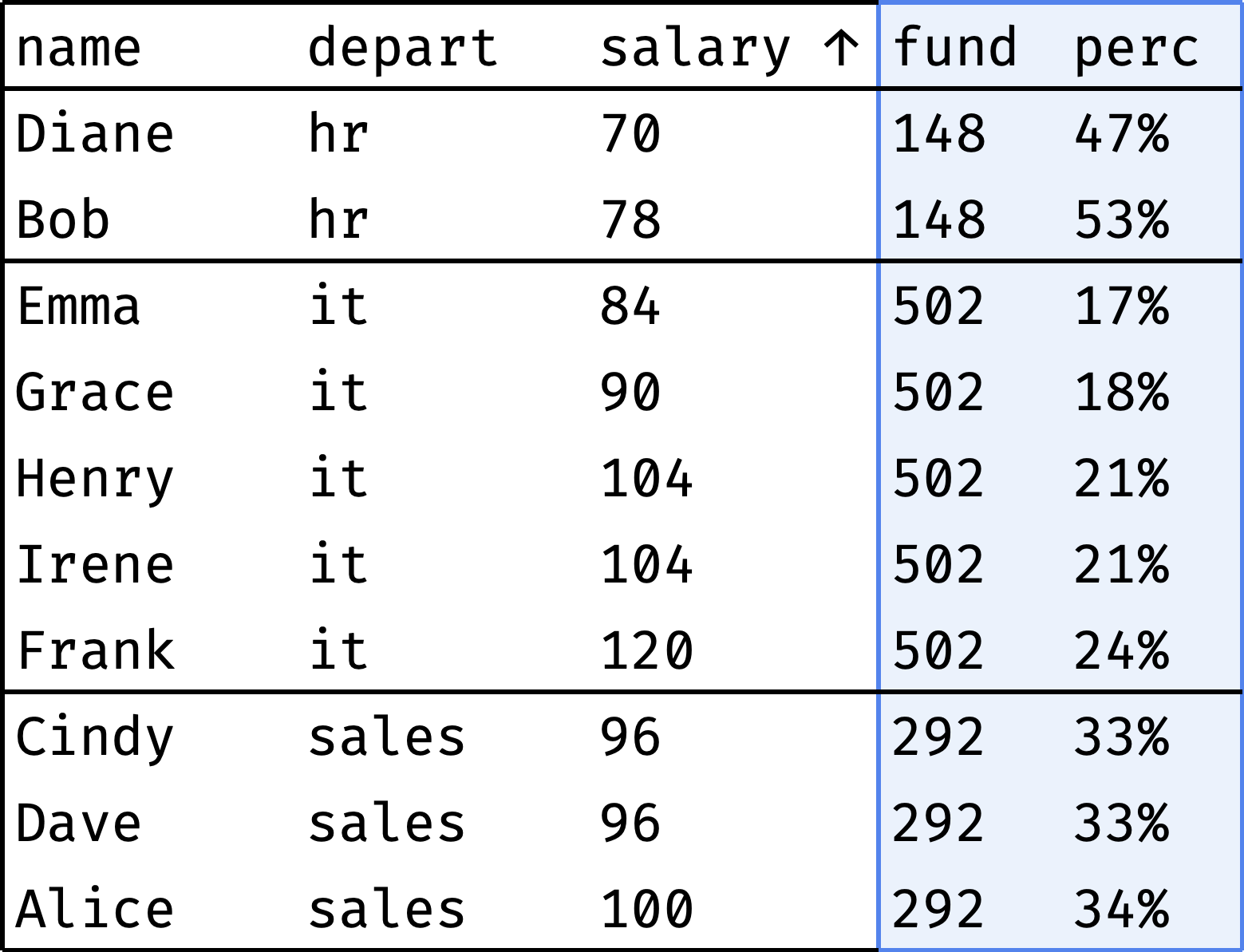
The fund column shows the department's salary fund, and the perc column shows the employee's salary share of that fund. As you can see, everything is more or less even in HR and Sales, but IT has a noticeable spread of salaries.
How do we go from "before" to "after"?
First, let's sort the table by department:
select
name, department, salary,
null as fund, null as perc
from employees
order by department, salary, id;
Now let's traverse from the first record to the last, computing the following values along the way:
fund— total departmental salary;perc— employee's salary as a percentage of thefund.
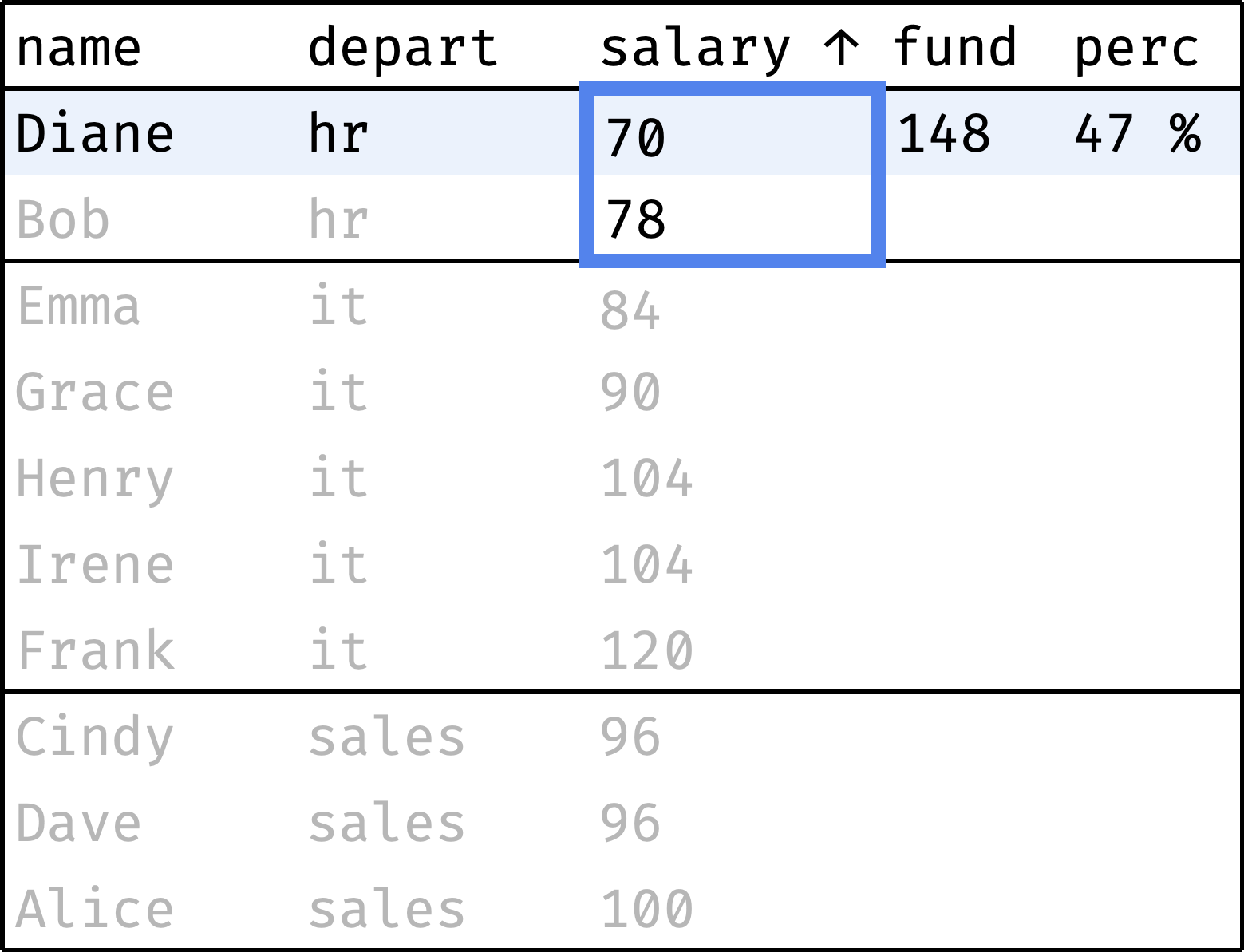
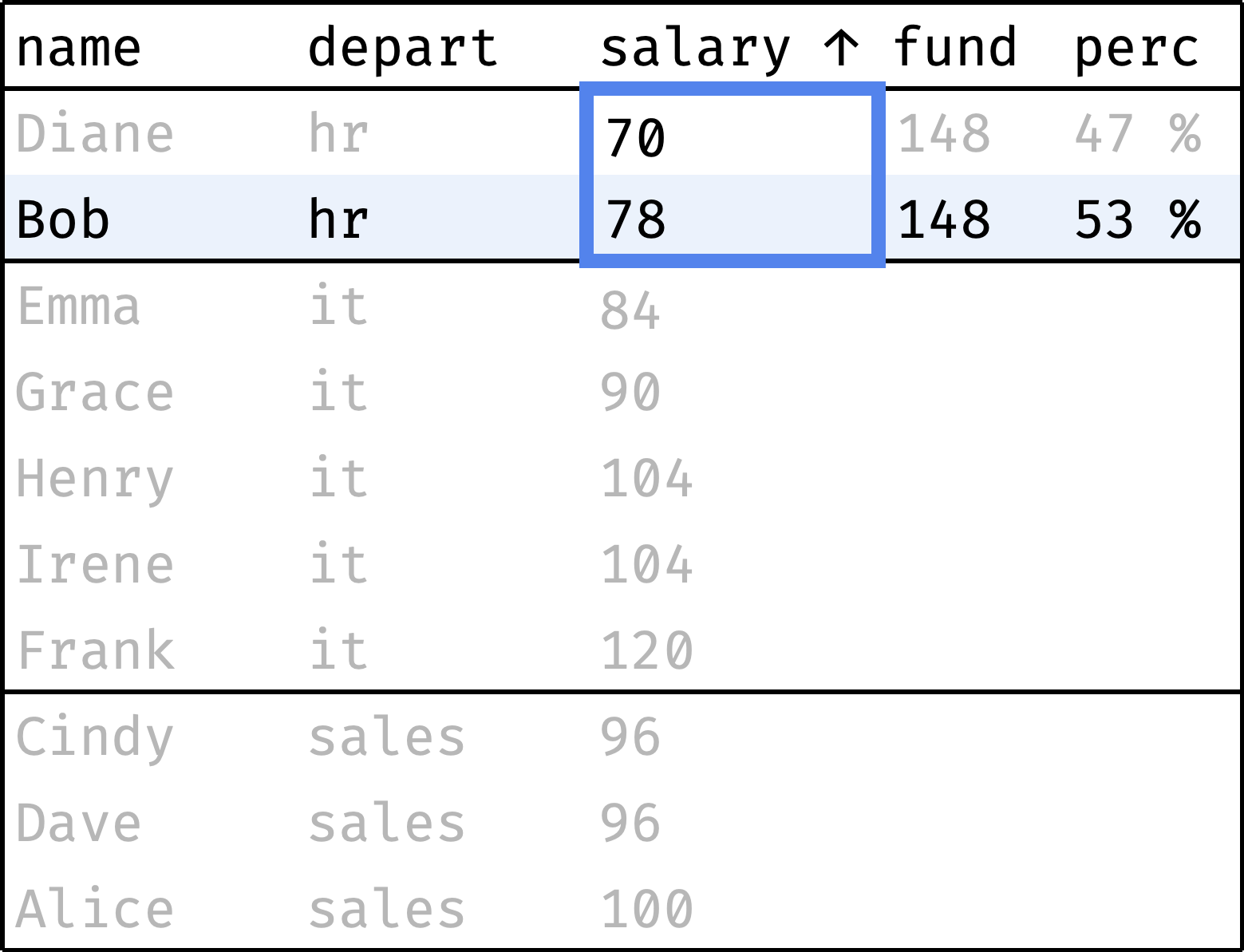
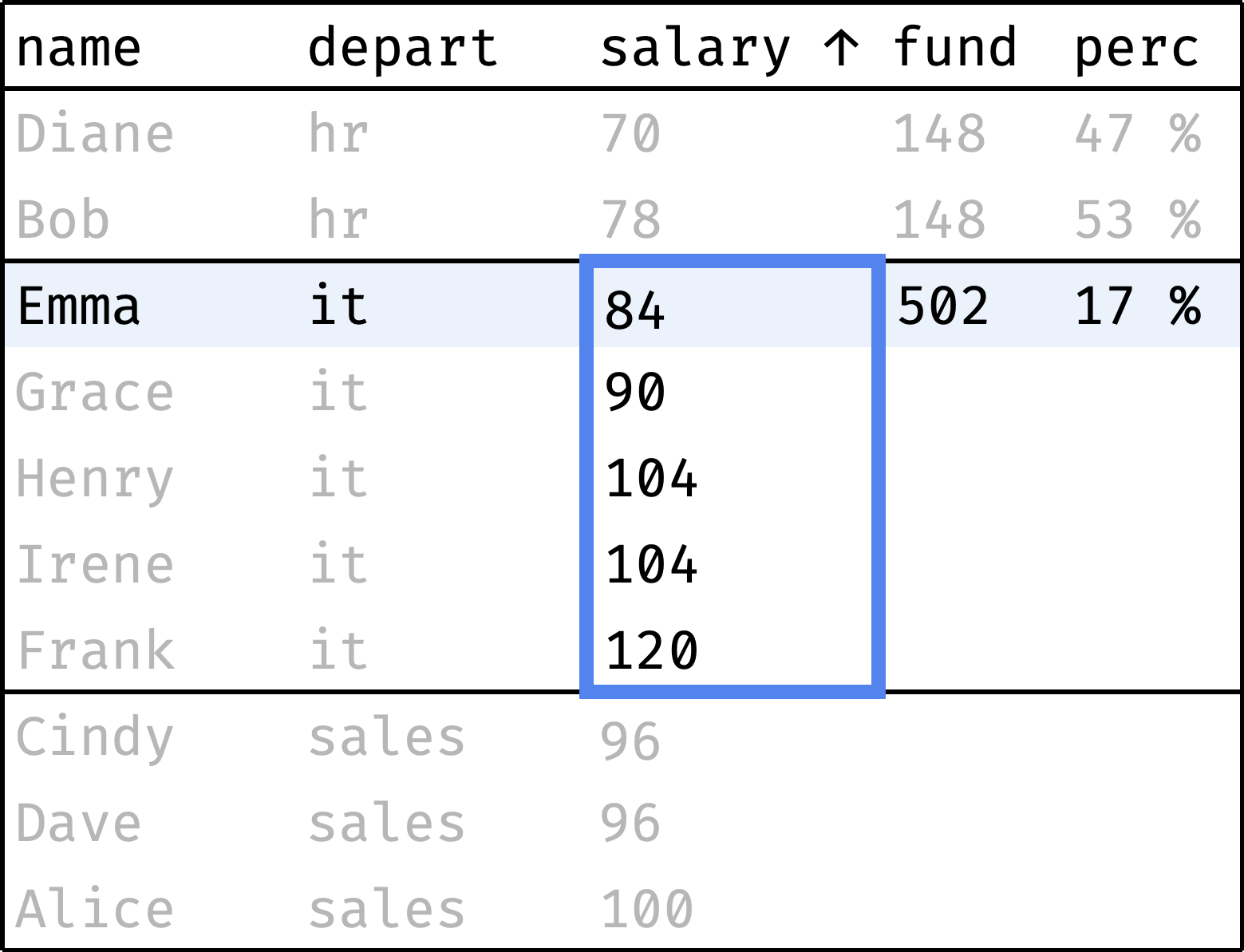
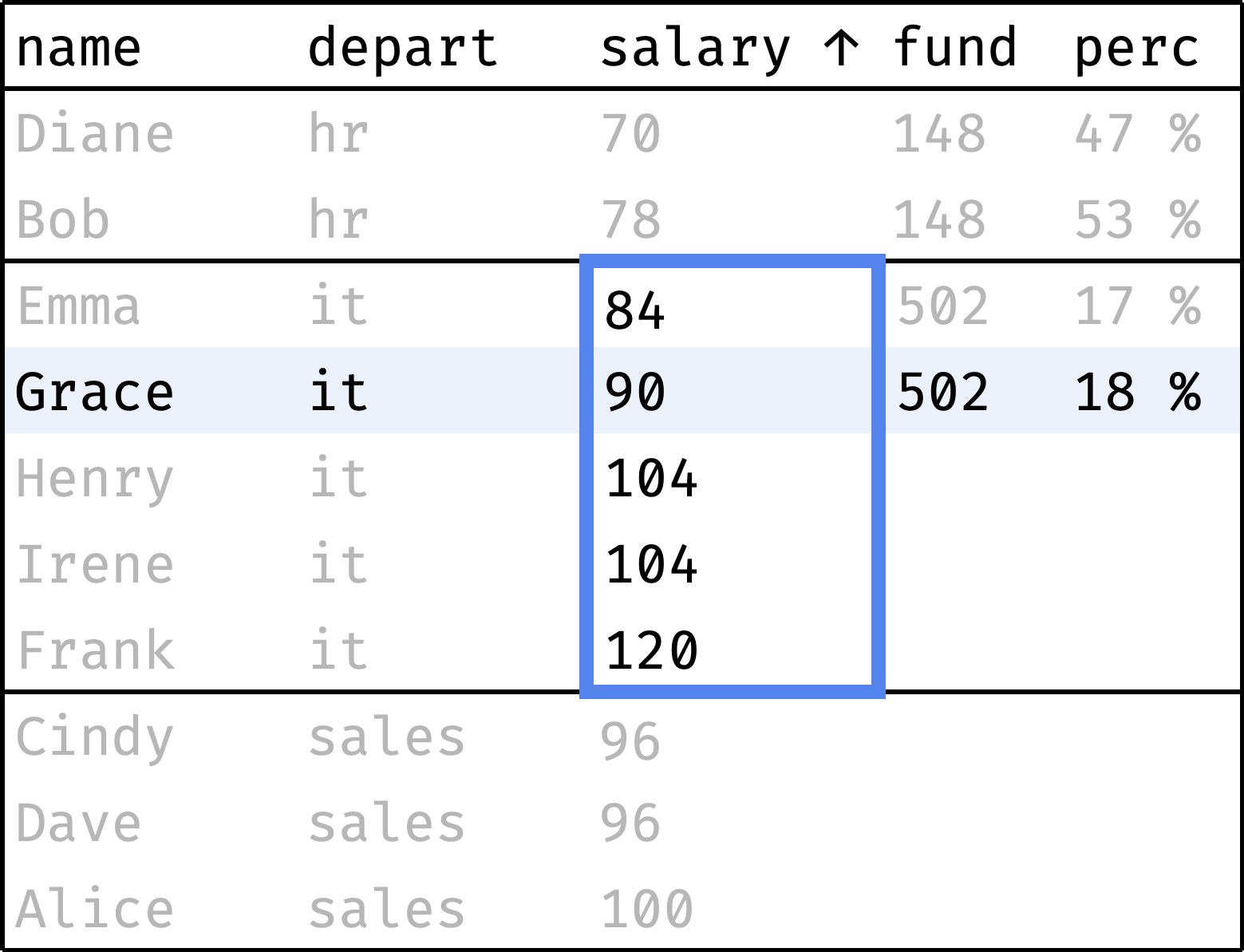
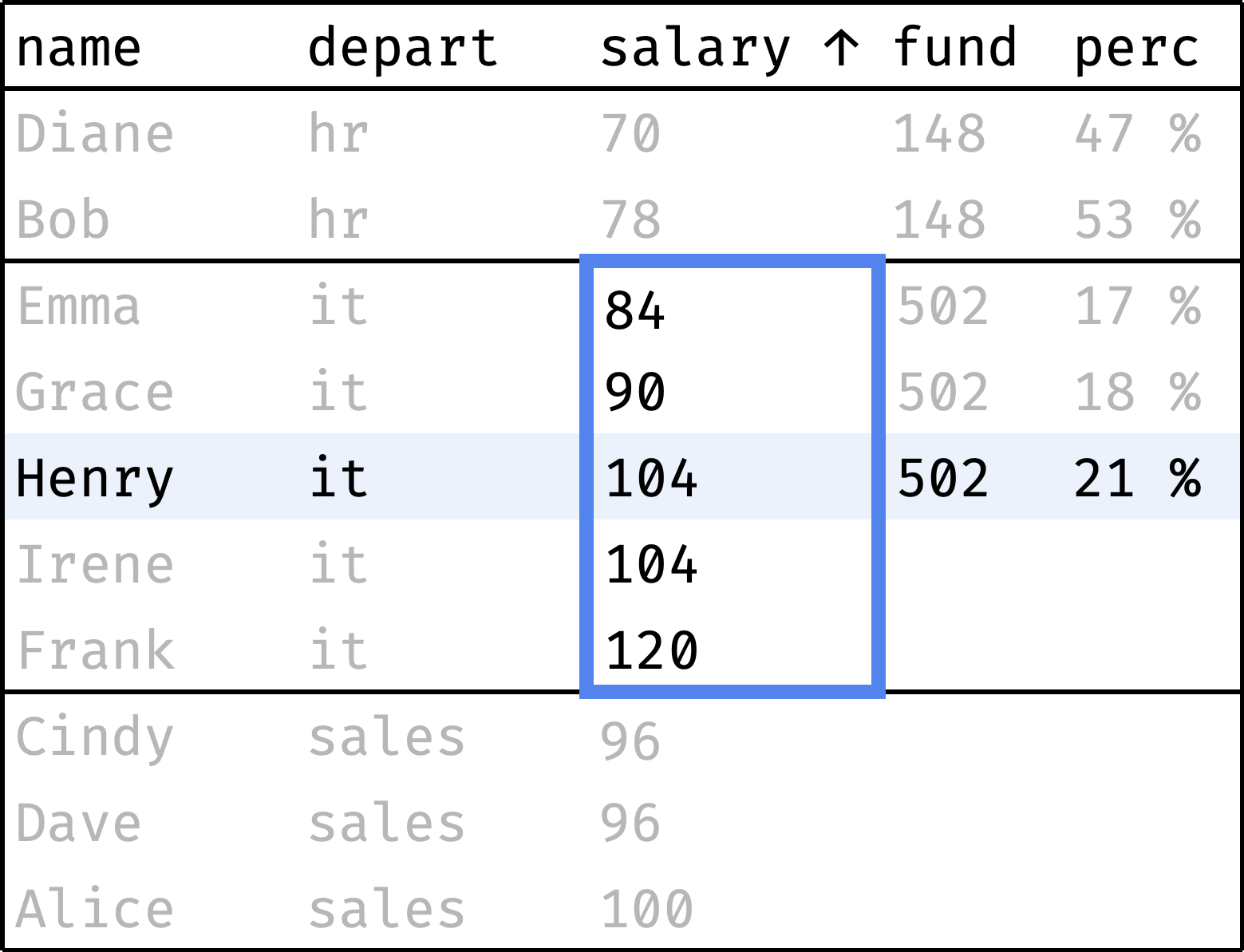
and so on...
In a single gif:

The window consists of several partitions, one partition per department. The order of records in a partition is not essential: we are counting the total salary, which does not depend on the order.
window w as (
partition by department
)
We can use a regular sum() over the window to calculate the fund. And the perc will be calculated as salary / fund:
select
name, department, salary,
sum(salary) over w as fund,
round(salary * 100.0 / sum(salary) over w) as perc
from employees
window w as (partition by department)
order by department, salary, id;
The sum() function works without surprises — it counts the sum of values for the entire partition to which the current row belongs.
✎ Exercise: City salary fund (+1 more)
Practice is crucial in turning abstract knowledge into skills, making theory alone insufficient. The book, unlike this article, contains a lot of exercises — that's why I recommend getting it.
If you are okay with just theory for now, let's continue.
Filtering and execution order
Let's get back to the query that calculated the salary fund by department:
select
name, department, salary,
sum(salary) over w as fund
from employees
window w as (partition by department)
order by department, salary, id;
Let's say we want to leave only London employees in the report. We'll add a filter:
select
name, salary,
sum(salary) over w as fund
from employees
where city = 'London'
window w as (partition by department)
order by department, salary, id;
The filter works. However, the fund values differ from the expected:
┌───────┬────────┬──────┐
│ name │ salary │ fund │
├───────┼────────┼──────┤
│ Diane │ 70 │ 148 │
│ Bob │ 78 │ 148 │
│ Emma │ 84 │ 502 │
│ Henry │ 104 │ 502 │
│ Dave │ 96 │ 292 │
└───────┴────────┴──────┘┌───────┬────────┬──────┐
│ name │ salary │ fund │
├───────┼────────┼──────┤
│ Diane │ 70 │ 148 │
│ Bob │ 78 │ 148 │
│ Emma │ 84 │ 188 │
│ Henry │ 104 │ 188 │
│ Dave │ 96 │ 96 │
└───────┴────────┴──────┘It's all about the order of operations. Here is the order in which the DB engine executes the query:
- Take the tables (
from) and join them if necessary (join). - Filter the rows (
where). - Group the rows (
group by). - Filter the aggregated results (
having). - Take specific columns from the result (
select). - Calculate the values of window functions (
function() over window). - Sort the results (
order by).
Windows are processed at the next-to-last step, after filtering and grouping the results. Therefore, in our query, the fund represents not the sum of all department salaries but the sum only for London employees.
The solution is to use a subquery with a window and filter it in the main query:
with emp as (
select
name, city, salary,
sum(salary) over w as fund
from employees
window w as (partition by department)
order by department, salary, id
)
select name, salary, fund
from emp where city = 'London';
Window definition
So far, we have described the window in the window clause and referred to it in the over clause:
select
name, department, salary,
count(*) over w as emp_count,
sum(salary) over w as fund
from employees
window w as (partition by department)
order by department, salary, id;
There is another way. SQL allows to omit the window clause and define the window directly inside over:
select
name, department, salary,
count(*) over (partition by department) as emp_count,
sum(salary) over (partition by department) as fund
from employees
order by department, salary, id;
I prefer the window clause — it is easier to read, and you can explicitly reuse the window. But the over option is common in the documentation and examples, so do not be surprised when you see it.
By the way, the window definition can be empty:
select
name, department, salary,
count(*) over () as emp_count,
sum(salary) over () as fund
from employees
order by department, salary, id;
An empty window includes all rows, so:
emp_countamounts to the total number of employees,fundamounts to the total salary for all employees.
✎ Exercise: Execution order (+1 more)
Practice is crucial in turning abstract knowledge into skills, making theory alone insufficient. The book, unlike this article, contains a lot of exercises — that's why I recommend getting it.
If you are okay with just theory for now, let's continue.
Aggregation functions
Here are the aggregation window functions:
| Function | Description |
|---|---|
min(value) | returns the minimum value across all window rows |
max(value) | returns the maximum value |
count(value) | returns the count of non-null values |
avg(value) | returns the average value |
sum(value) | returns the total value |
group_concat(value, separator) | returns a string combining values using separator (SQLite and MySQL only) |
string_agg(value, separator) | similar to group_concat() in PostgreSQL and MS SQL |
Keep it up
You have learned how to calculate regular window aggregates. In the next chapter we will try rolling aggregates!
★ Subscribe to keep up with new posts.