Ranking data with SQL window functions
This is an excerpt from my book SQL Window Functions Explained. The book is a clear and visual introduction to the topic with lots of practical exercises.
Ranking means coming up with all kinds of ratings, from the winners of the World Swimming Championships to the Forbes 500.
We will rank records from the toy employees table:
┌────┬───────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼───────┼────────┼────────────┼────────┤
│ 11 │ Diane │ London │ hr │ 70 │
│ 12 │ Bob │ London │ hr │ 78 │
│ 21 │ Emma │ London │ it │ 84 │
│ 22 │ Grace │ Berlin │ it │ 90 │
│ 23 │ Henry │ London │ it │ 104 │
│ 24 │ Irene │ Berlin │ it │ 104 │
│ 25 │ Frank │ Berlin │ it │ 120 │
│ 31 │ Cindy │ Berlin │ sales │ 96 │
│ 32 │ Dave │ London │ sales │ 96 │
│ 33 │ Alice │ Berlin │ sales │ 100 │
└────┴───────┴────────┴────────────┴────────┘
Table of contents:
- Window function
- Window ordering vs. result ordering
- Sorting uniqueness
- Multiple windows
- Partitions
- Groups
- Ranking functions
- Keep it up
Databases
All modern relational databases support window functions to some extent. I tested this article on three of them:
- MySQL 8.0.2+ (MariaDB 10.2+)
- PostgreSQL 11+
- SQLite 3.28+
Windows are fully implemented in PostgreSQL, and almost fully in SQLite. MySQL has all the core features but lacks some of the advanced ones.
Oracle 11g+, MS SQL 2012+, and Google BigQuery are also fine. They lack certain advanced capabilities, just like MySQL. If you use one of them — the article will also be helpful.
You can use any of the mentioned DBMS if you have one available. Or an online playground.
Window function
Let's rank employees by salary:
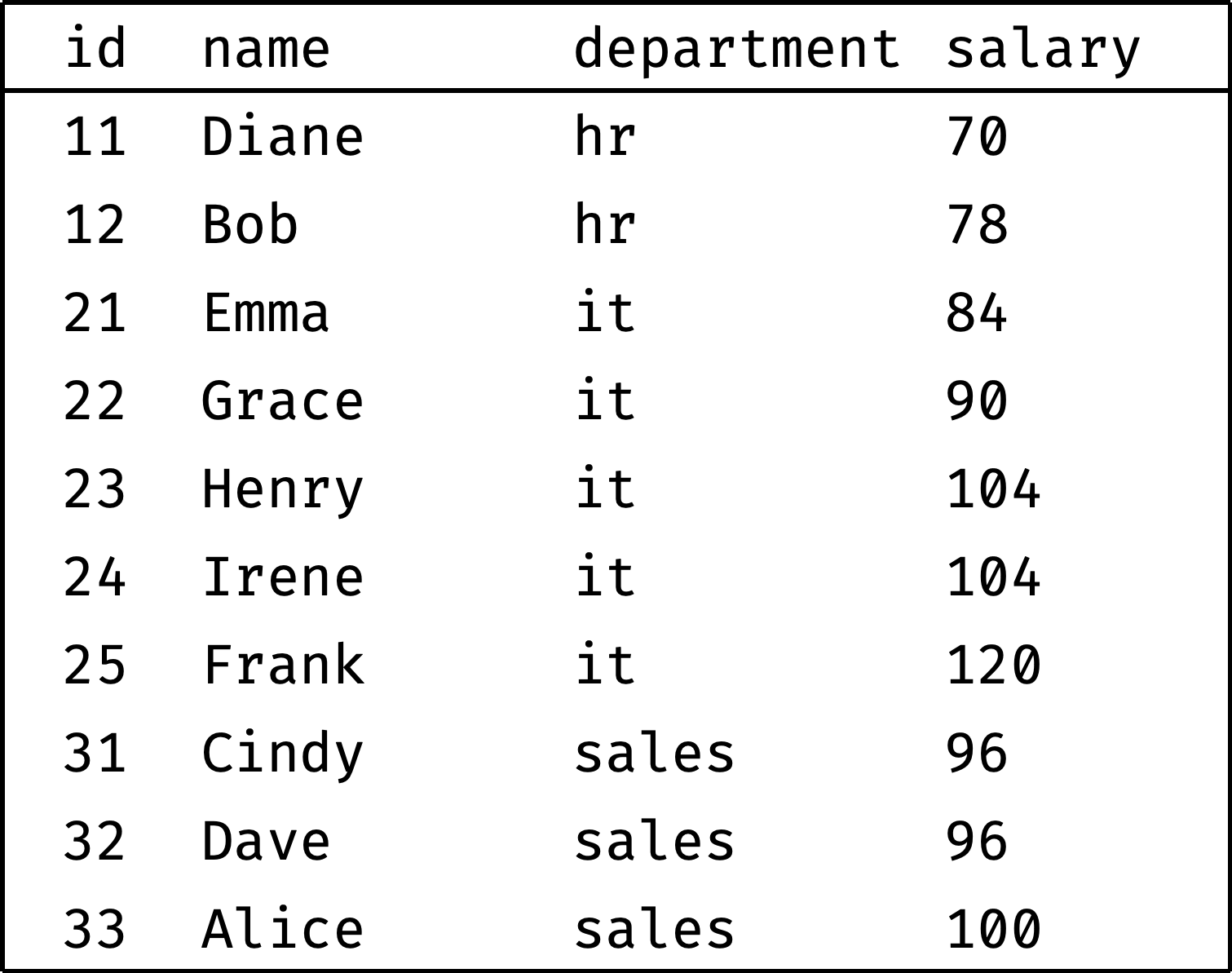
Note that employees with the same salary received the same rank (Henry and Irene, Cindy and Dave).
How do we go from "before" to "after"?
First, let's sort the table in descending order of salary:
select
null as "rank",
name, department, salary
from employees
order by salary desc, id;
Now let's go from the first row to the last and calculate the rank of each record. We will start with one and increase the rank every time the salary value is less than the previous one:
and so on...
To compute the rank, at each step we will look at the salary values, highlighted with a blue frame. Let's call these values a window.
Let's describe the window contents in plain English:
- These are the values of the salary column.
- They are ordered from larger to smaller values.
Let's express it in SQL:
window w as (order by salary desc)
window— a keyword announcing that the window definition will follow;w— the name of the window (could be anything);(order by salary desc)— the window definition ("values of the salary column in descending order").
Our goal is to calculate the rank over the window w. In SQL, this is written as dense_rank() over w.
dense_rank() is a window function that counts the rank over the specified window. The logic of dense_rank() is the same as when we counted manually — start with one and increase the rank every time the next window value differs from the previous one.
Let's add the window definition and the window function to the original query:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by "rank", id;
Here's how the engine executes this query:
- Take the table specified in
from. - Select all records from it.
- Calculate the value of
dense_rank()for each record using the windoww. - Sort the result as specified in
order by.
Here's an animation of how the engine executes step 3, where the rank is assigned:
The window clause itself does not affect query results. It only defines the window that we can use in the query. If we remove the dense_rank() call, the query will work as if there is no window:
select
null as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by salary desc, id;
The window starts working only when a window function in select uses it.
Window queries in Oracle and MS SQL Server databases
Neither Oracle nor SQL Server support the window clause. To make a window query work in these databases, move the window definition inside the over clause.
Instead of this:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by "rank", id;
Do this:
select
dense_rank() over (
order by salary desc
) as "rank",
name, department, salary
from employees
order by "rank", id;Window ordering vs. result ordering
People often have questions about window sorting. Let's break them down.
Here is a query that calculates a salary rating:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by "rank", id;
Let's leave the order by in the window but remove it from the main query:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc);
Nothing has changed. So why use order by in the main query?
The window's order by defines the window sorting, while the main query's order by defines the final result sorting after the rest of the query is complete.
Let's say we want to assign a rank in descending order of salary but sort in the opposite, ascending order:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by salary asc;
As you can see, the rank is assigned according to the window sorting (salary desc), and the results are ordered according to the main query sorting (salary asc).
If the query's order by clause is not specified, the result order is undefined. Sometimes it might work out (as in the example with the ascending salary ranking), and sometimes it might not. It's not worth relying on luck, so always specify the order of results explicitly.
Sorting uniqueness
Another common question is why to include the id column in the result ordering:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by "rank", id;
Why use order by rank, id instead of order by rank? To know how to sort employees with the same rank. Without the id, the order of records "Henry-Irene" and "Cindy-Dave" is undefined, and the DB engine can arrange them in any order. But with the id, everything is clear: "Henry, then Irene" and "Cindy, then Dave".
✎ Exercise: Ranking by name
Practice is crucial in turning abstract knowledge into skills, making theory alone insufficient. The book, unlike this article, contains a lot of exercises — that's why I recommend getting it.
If you are okay with just theory for now, let's continue.
Multiple windows
Another common question (not related to sorting) is how to define multiple windows in a query.
The answer is to write them in a comma-separated fashion in the window clause:
select ...
from ...
where ...
window
w1 as (...),
w2 as (...),
w3 as (...)
;
For example, let's rank employees by salary both in ascending and descending order:
select
dense_rank() over w1 as r_asc,
dense_rank() over w2 as r_desc,
name, salary
from employees
window
w1 as (order by salary asc),
w2 as (order by salary desc)
order by salary, id;
Partitions
Let's rank employees by salary for each department independently:
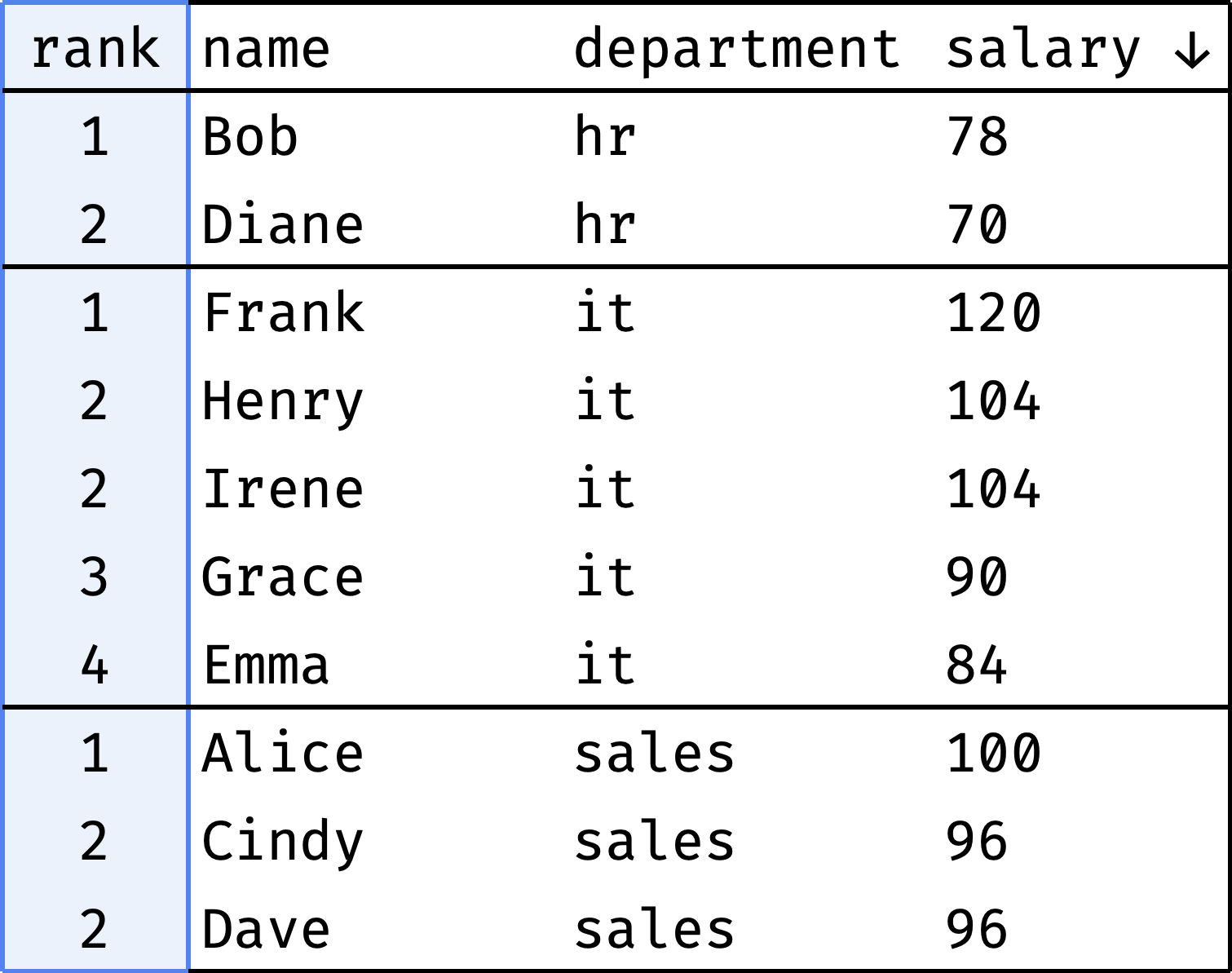
How do we go from "before" to "after"?
First, let's sort the table by department. Within the same department, let's sort in descending order of salary:
select
null as "rank",
name, department, salary
from employees
order by department, salary desc, id;
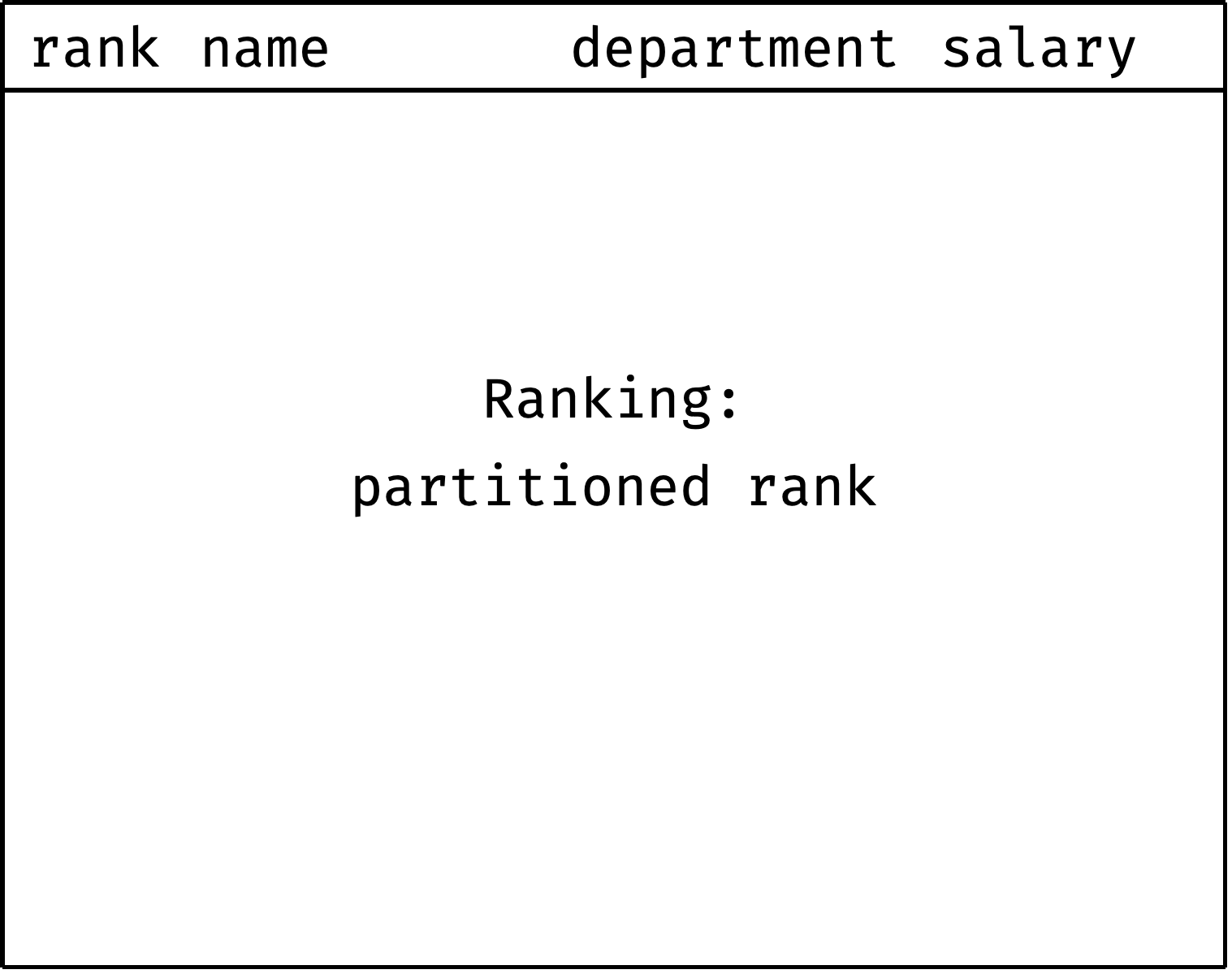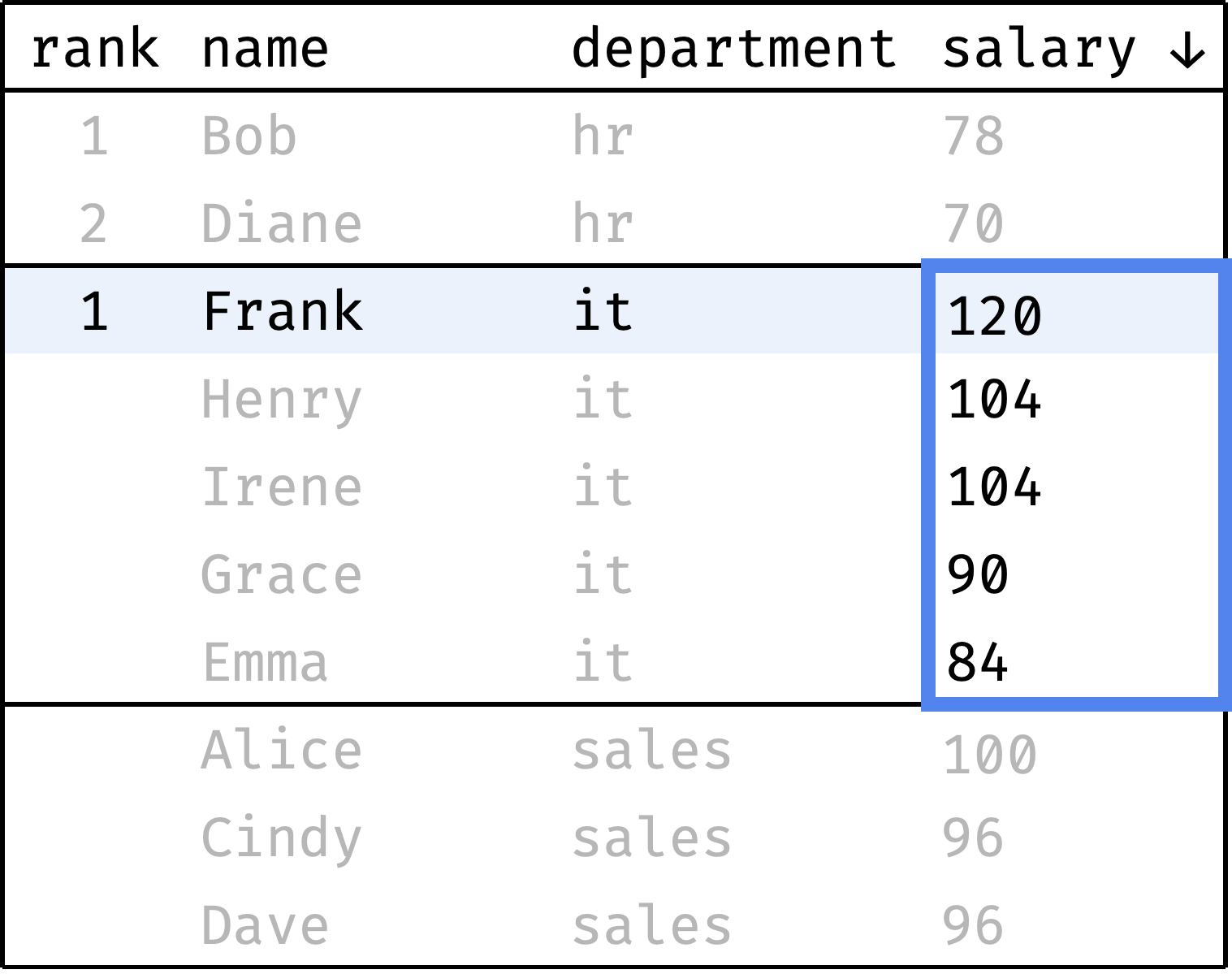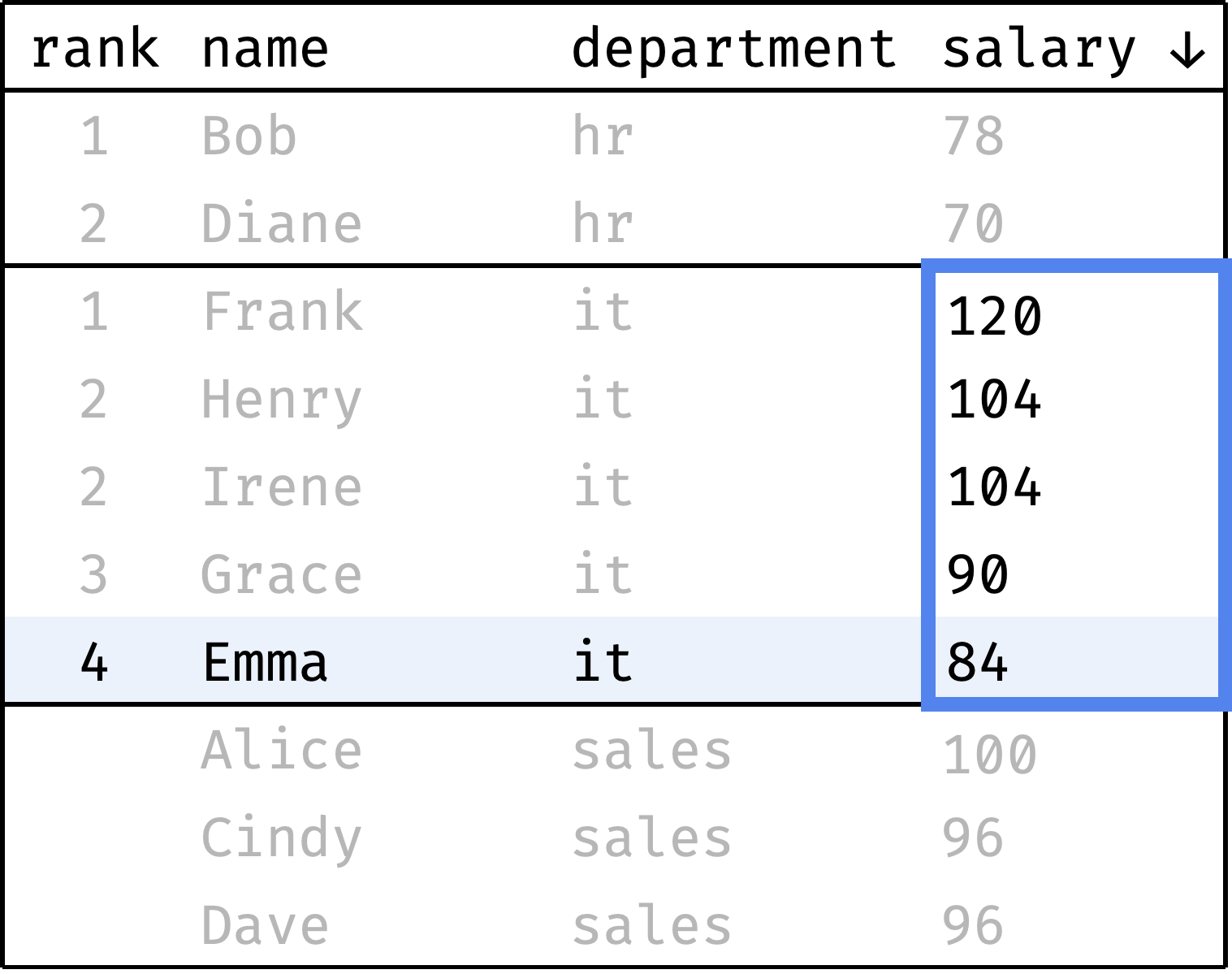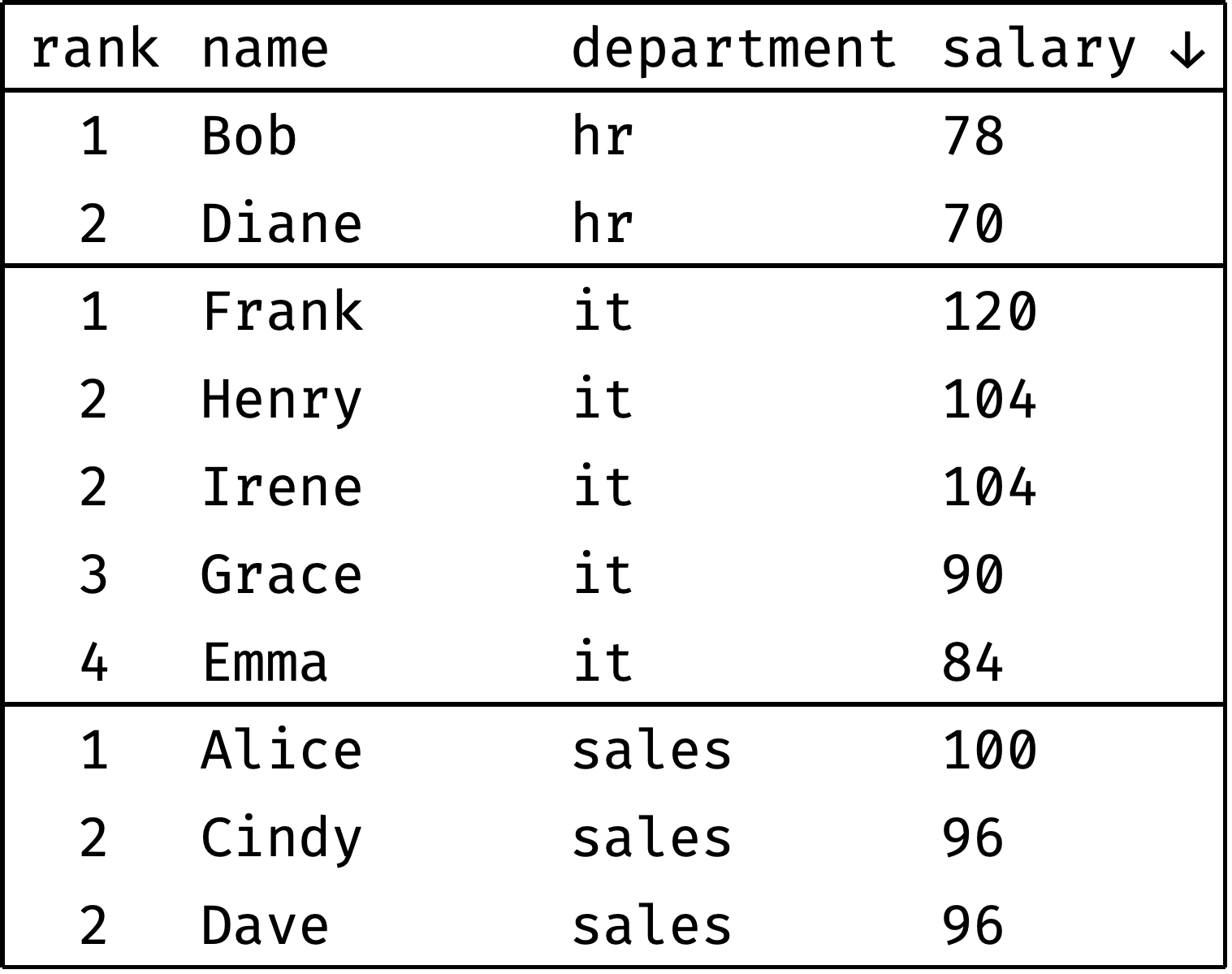
Now let's go from the first row to the last and calculate the rank of each record. We will start with one and increase the rank every time the salary value is less than the previous one. When switching between departments, we will reset the rank back to 1:
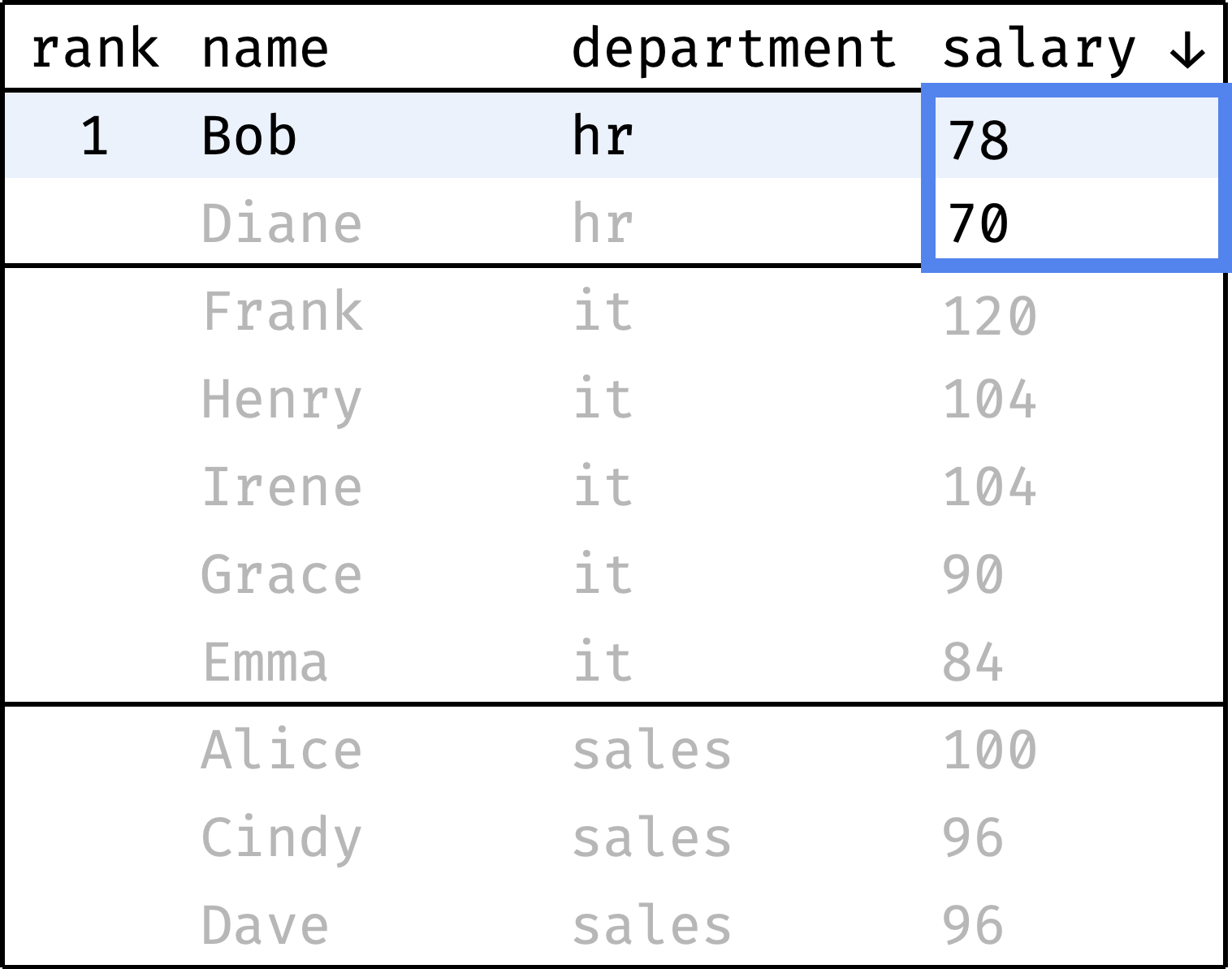
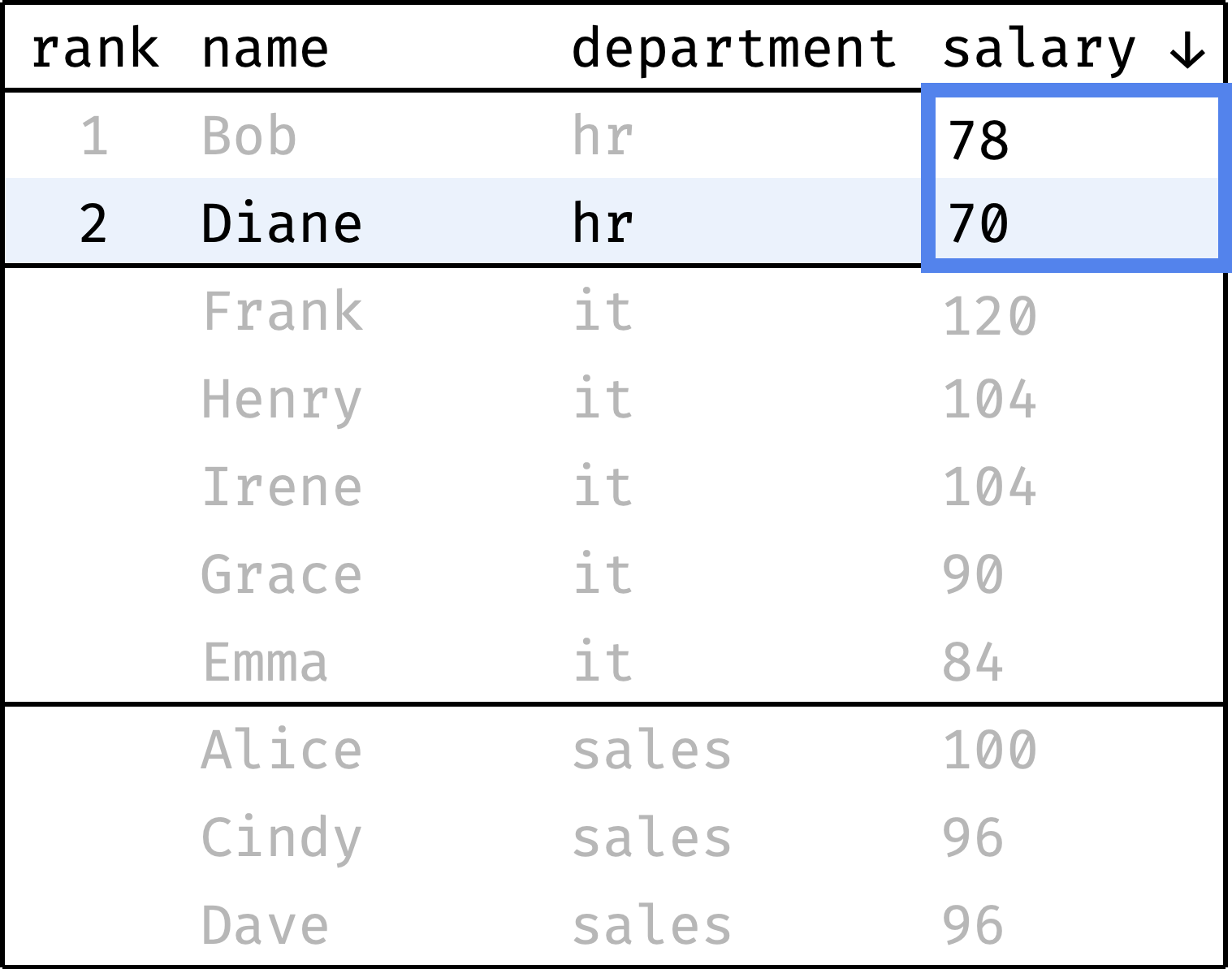
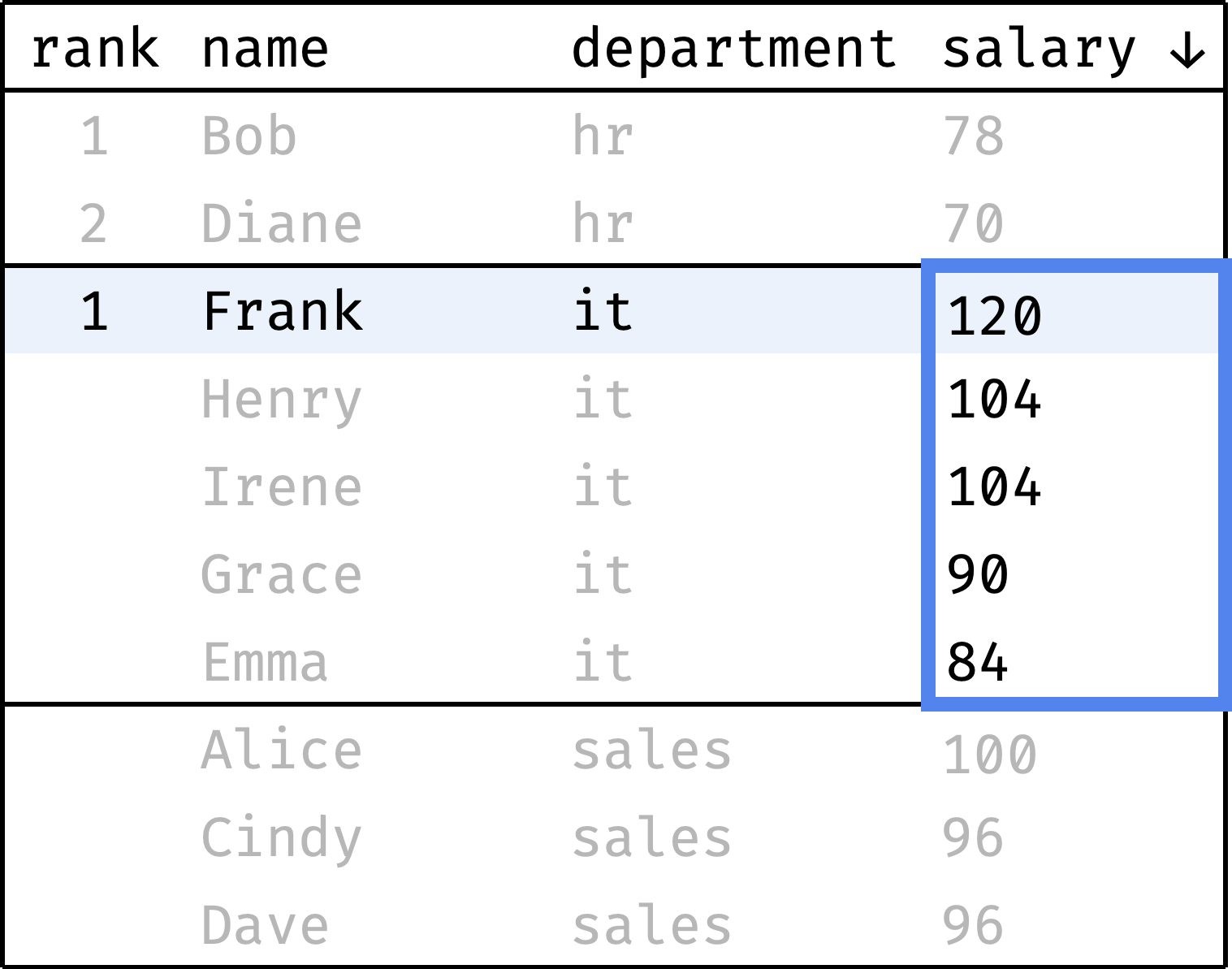
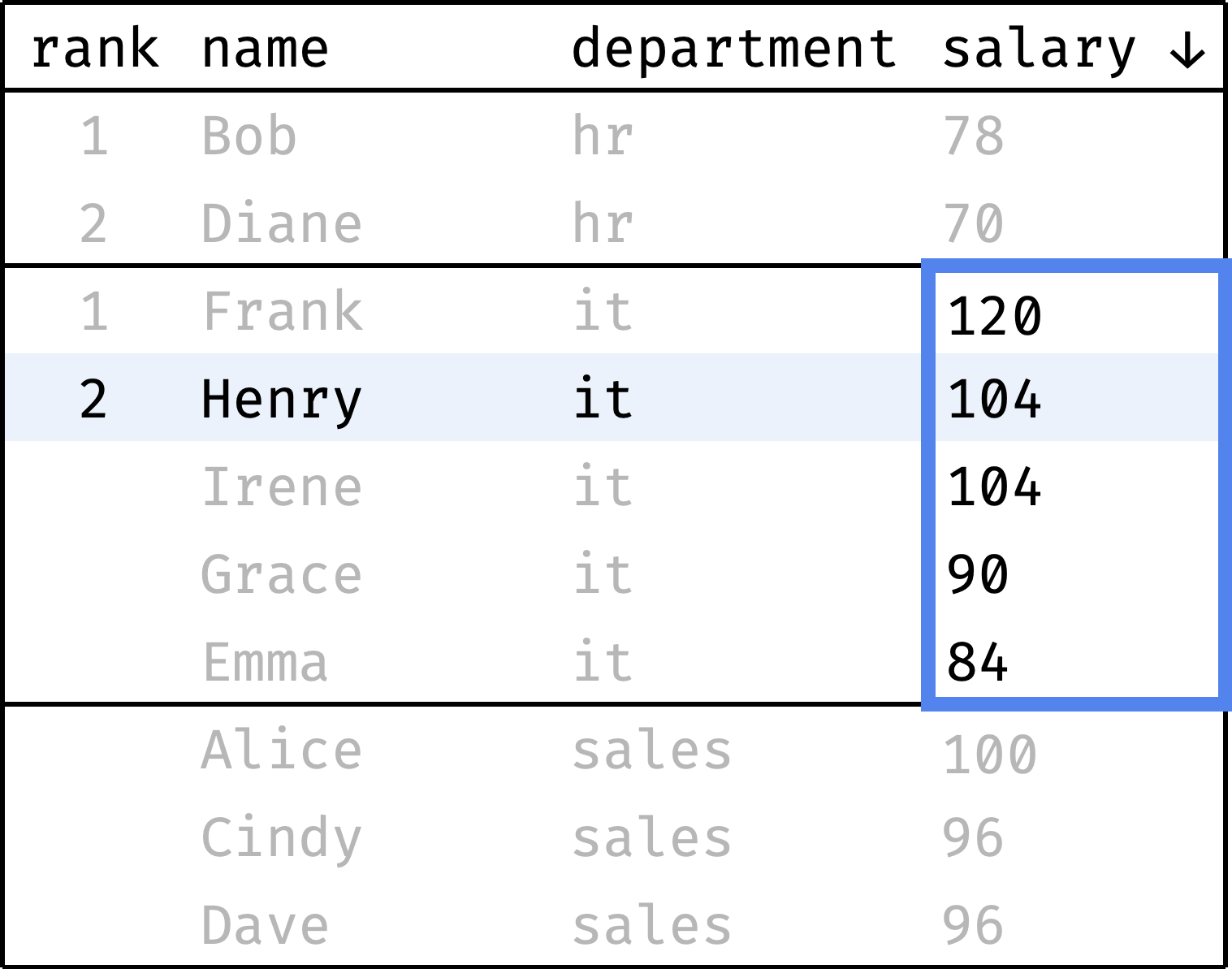
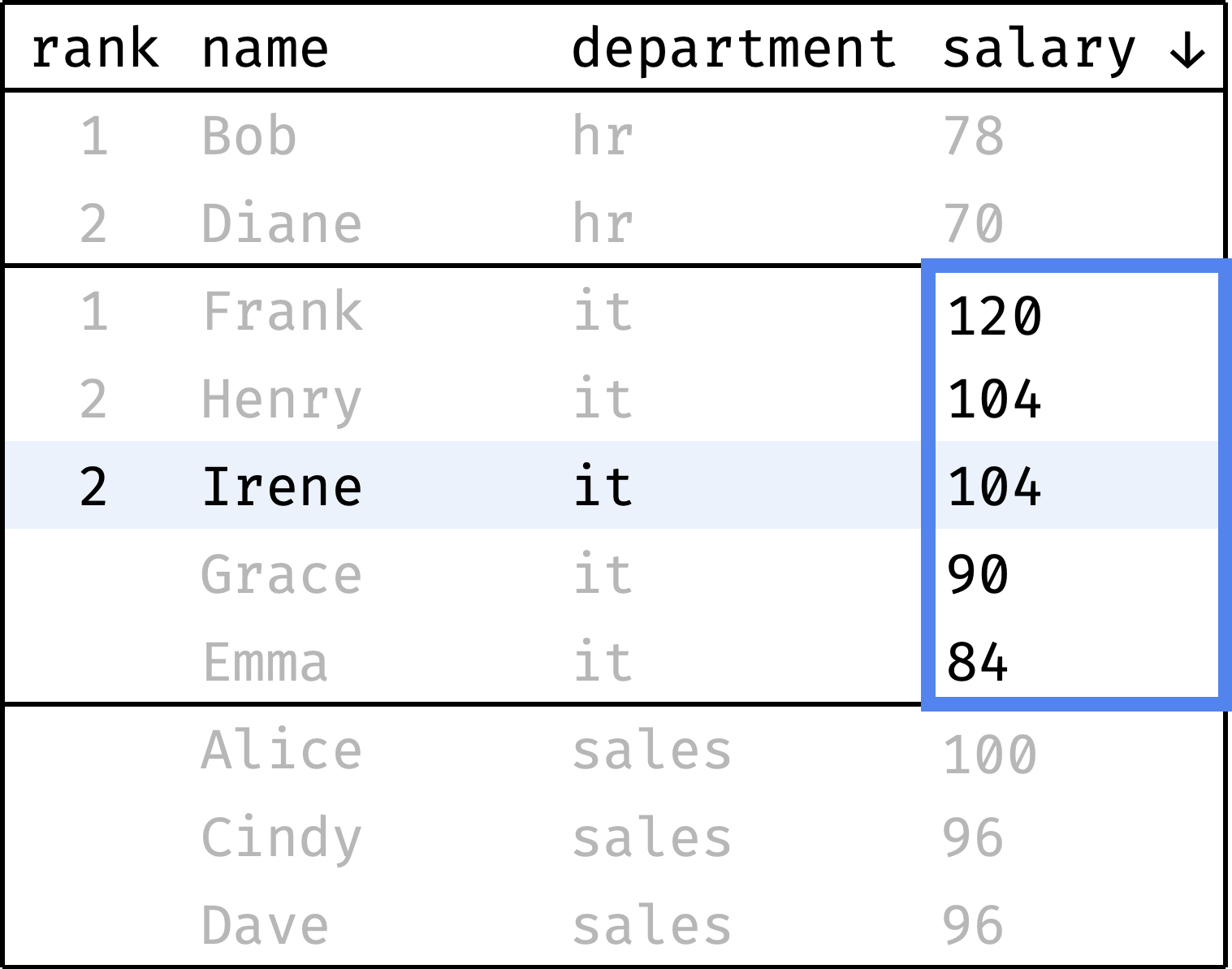
and so on...
To compute the rank, at each step we will look at the salary values, highlighted with a blue frame. It is the window in this case.
The window changes depending on which department the current record belongs to. Let's describe it in plain English:
- The window is split into several independent partitions — one for each department.
- Inside each partition, records are ordered by decreasing salary.
Let's express it in SQL:
window w as (
partition by department
order by salary desc
)
partition by departmentspecifies how to split the window into partitions;order by salary descsets the sorting within the partition.
The rank calculation function remains the same — dense_rank().
Let's add the window definition and the window function to the original query:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (
partition by department
order by salary desc
)
order by department, "rank", id;
Here's an animation showing how the engine calculates the rank for each record:
✎ Exercise: Salary rating by city
Practice is crucial in turning abstract knowledge into skills, making theory alone insufficient. The book, unlike this article, contains a lot of exercises — that's why I recommend getting it.
If you are okay with just theory for now, let's continue.
Groups
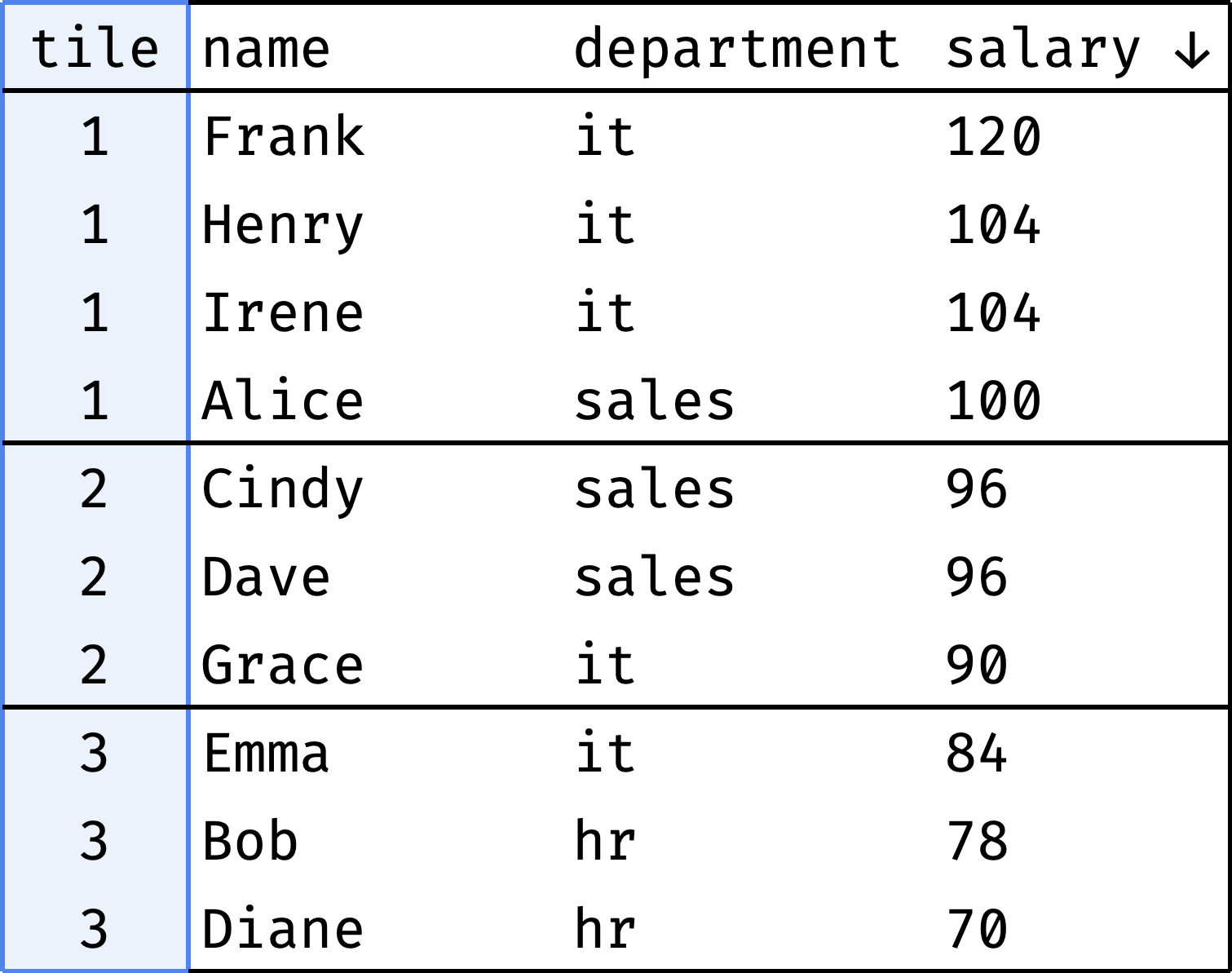
Let's divide the employees into three groups according to their salary:
- high-paid,
- medium-paid,
- low-paid.
How do we go from "before" to "after"?
First, let's sort the table in descending order of salary:
select
null as tile,
name, department, salary
from employees
order by salary desc, id;
There are 10 records and 3 groups — which means two groups of 3 records and one of 4 records. For example:
┌──────┬───────┬────────────┬────────┐
│ tile │ name │ department │ salary │
├──────┼───────┼────────────┼────────┤
│ │ Frank │ it │ 120 │
│ │ Henry │ it │ 104 │
│ │ Irene │ it │ 104 │
│ │ Alice │ sales │ 100 │
├──────┼───────┼────────────┼────────┤
│ │ Cindy │ sales │ 96 │
│ │ Dave │ sales │ 96 │
│ │ Grace │ it │ 90 │
├──────┼───────┼────────────┼────────┤
│ │ Emma │ it │ 84 │
│ │ Bob │ hr │ 78 │
│ │ Diane │ hr │ 70 │
└──────┴───────┴────────────┴────────┘
To draw the boundaries between the groups, we must analyze all the salaries, sorted in descending order. Therefore, the window is the same as we used for salary rating:
window w as (order by salary desc)
But the function is different — ntile(n), where n is the number of groups. In our case n = 3:
select
ntile(3) over w as tile,
name, department, salary
from employees
window w as (order by salary desc)
order by salary desc, id;
ntile(n) splits all records into n groups and returns the group number for each record. If the total number of records (10 in our case) is not divisible by the group size (3), then the former groups will be larger than the latter.
ntile() always tries to split the data so that the groups are of the same size. So records with the same salary value may end up in different (adjacent) groups:
select
ntile(2) over w as tile,
name, department, salary
from employees
window w as (order by salary desc, id)
order by salary desc, tile;
┌──────┬───────┬────────────┬────────┐
│ tile │ name │ department │ salary │
├──────┼───────┼────────────┼────────┤
│ 1 │ Frank │ it │ 120 │
│ ... │ ... │ ... │ ... │
│ 1 │ Cindy │ sales │ 96 │ <-- (!)
├──────┼───────┼────────────┼────────┤
│ 2 │ Dave │ sales │ 96 │ <-- (!)
│ ... │ ... │ ... │ ... │
│ 2 │ Diane │ hr │ 70 │
└──────┴───────┴────────────┴────────┘
✎ Exercises: Salary groups in cities (+1 more)
Practice is crucial in turning abstract knowledge into skills, making theory alone insufficient. The book, unlike this article, contains a lot of exercises; that's why I recommend getting it.
If you are okay with just theory for now, though — let's continue.
Ranking functions
Here are the ranking window functions:
| Function | Description |
|---|---|
row_number() | returns the row ordinal number |
dense_rank() | returns row rank |
rank() | returns row rank with possible gaps (see below) |
ntile(n) | splits all rows into n groups and returns the index of the group that the row belongs to |
We have already seen dense_rank() and ntile().
row_number() numbers the rows in the order specified in order by. No surprises here.
rank() is similar to dense_rank(), and the difference is easier to explain with an example.
select
••• over w as "rank",
name, salary
from employees
window w as (order by salary desc)
order by "rank", id;
Let's try substituting ••• with dense_rank() and rank():
┌──────┬───────┬────────┐
│ rank │ name │ salary │
├──────┼───────┼────────┤
│ 1 │ Frank │ 120 │
│ 2 │ Henry │ 104 │
│ 2 │ Irene │ 104 │
│ 3 │ Alice │ 100 │ (!)
│ 4 │ Cindy │ 96 │
│ 4 │ Dave │ 96 │
│ 5 │ Grace │ 90 │ (!)
│ 6 │ Emma │ 84 │
│ 7 │ Bob │ 78 │
│ 8 │ Diane │ 70 │
└──────┴───────┴────────┘┌──────┬───────┬────────┐
│ rank │ name │ salary │
├──────┼───────┼────────┤
│ 1 │ Frank │ 120 │
│ 2 │ Henry │ 104 │
│ 2 │ Irene │ 104 │
│ 4 │ Alice │ 100 │ (!)
│ 5 │ Cindy │ 96 │
│ 5 │ Dave │ 96 │
│ 7 │ Grace │ 90 │ (!)
│ 8 │ Emma │ 84 │
│ 9 │ Bob │ 78 │
│ 10 │ Diane │ 70 │
└──────┴───────┴────────┘dense_rank() assigns Alice the third place, while rank() assigns the fourth because Henry and Irene already occupied the second and third. It is the same with Grace after Cindy and Dave. That's the whole difference.
Keep it up
You have learned what "window" and "window functions" are and how to use them to rank data. In the next chapter, we will deal with window offsets and comparisons!
Subscribe to keep up with new posts.